Deep Learning là gì? Bài viết này giải thích đơn giản và ngắn gọn về Deep Learning, đặc biệt dành cho những ai chưa hiểu rõ về khái niệm này.
Artificial Intelligence (AI) và Machine Learning (ML) là một trong những chủ đề hot nhất hiện nay, chúng được nhắc đến rất nhiều trên Internet.
Thuật ngữ AI cũng xuất hiện trong các cuộc nói chuyện hằng ngày, chẳng hạn như bạn nghe ai đó nói về chuyện muốn học AI, bạn nghe các giám đốc, các quản lý, các start-up nói rằng họ muốn dùng AI để cung cấp các dịch vụ của họ. Tuy nhiên vấn đề là hầu hết những người này vẫn chưa hiểu rõ AI là gì.
Vậy hãy theo dõi bài viết này để giải đáp các câu hỏi trên cũng như nắm được cách mà Deep Learning - một loại ML phổ biến nhất hiện nay hoạt động thế nào nhé.
Kiến thức nền
Bước đầu tiên để hiểu cách mà Deep Learning hoạt động là nhận dạng được những điểm khác biệt giữa một số thuật ngữ quan trọng.
Artificial Intelligence với Machine Learning
Artificial Intelligence là sự sao chép trí thông minh của con người (Human Intelligence) vào trong máy tính.
Khi nghiên cứu về AI lần đầu tiên được thực hiện, các nhà nghiên cứu đã cố gắng sao chép trí thông minh của con người cho những công việc cụ thể - ví dụ như chơi một trò chơi.
Họ đưa ra rất nhiều quy tắc và các máy tính cần phải tuân thủ. Máy tính có một danh sách cụ thể các hoạt động có khả năng thực hiện, và đưa ra quyết định dựa trên những quy tắc này.
Machine Learning ám chỉ khả năng học tập của một máy móc bằng cách sử dụng các bộ (set) dữ liệu rất lớn thay vì những quy tắc không thể sửa đổi (hard-core)
ML cho phép các máy tính có thể tự học. Loại học này tận dụng sức mạnh xử lý của các máy tính hiện đại - những thiết bị mà có thể dễ dàng xử lý các set dữ liệu lớn.
Supervised Learning vs unsupervised learning
Supervised Learning liên quan đến việc sử dụng các bộ dữ liệu đã được gán mà có đầu vào (Input) và các đầu ra (Output) được kỳ vọng.
Khi bạn dạy một AI bằng cách sử dụng Supervised Learning, nghĩa là bạn đã cho nó một đầu vào và nói với nó đầu ra mong đợi của bạn.
Nếu đầu ra được tạo bởi AI là sai thì nó sẽ phải điều chỉnh lại các tính toán của nó. Quá trình này được thực hiện một cách lặp đi lặp lại trên bộ dữ liệu đó cho tới khi AI không gây ra lỗi nào nữa.
Một ví dụ về Supervised Learning đó là AI dự báo thời tiết. Nó học cách dự báo thời tiết bằng cách sử dụng dữ liệu lịch sử. Dữ liệu để dạy gồm có các Input (áp lực, độ ẩm, tốc độ gió) và Output (nhiệt độ).
Unsupervised Learning là cách dạy các AI bằng cách sử dụng các bộ dữ liệu mà không có cấu trúc cụ thể.
Khi bạn dạy một AI bằng cách sử dụng Unsupervised Learning, bạn để cho AI tự phân loại dữ liệu một cách logic.
Một ví dụ về Unsupervised Learning đó là AI dự đoán hành vi cho một trang web thương mại điện tử. Nó không học bằng cách dùng một bộ dữ liệu đầu vào và đầu ra đã được gán.
Thay vào đó, nó sẽ tạo ra các phân loại dữ liệu đầu cài của riêng nó. Nó sẽ nói với bạn loại người dùng nào có khả năng nhất sẽ mua các sản phẩm khác nhau.
Vậy thì Deep Learning hoạt động như thế nào?
Với các kiến thức nền ở trên, bạn đã sẵn sàng để tìm hiểu về Deep Learning là gì và cách mà nó làm việc.
Về cơ bản, Deep Learning là một phương pháp học máy (ML). Nó cho phép chúng ta dạy một AI dự đoán đầu ra dựa trên một bộ đầu vào. Cả hai loại Supervised và Unsupervised Learning đều có thể được sử dụng để dạy AI.
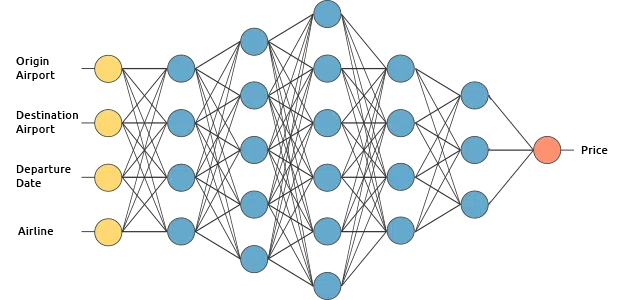
Để tìm hiểu cách Deep Learning hoạt động, chúng ta hãy thử xây dựng một dịch vụ dự đoán giá vé máy bay. Chúng ta sẽ dạy cho AI bằng cách dùng phương pháp Supervised Learning.
Chúng ta muốn AI dự đoán vé máy bay dự đoán giá bằng cách sử dụng những đầu vào sau (để đơn giản, chúng ta sẽ loại bỏ các vé khứ hồi):
- Origin Airport (điểm khởi hành)
- Destination Airport (điểm đến)
- Departure Date (thời gian khởi hành)
- Airline (hãng máy bay)
Mạng Neuron nhân tạo (Neural networks)
Bây giờ, hãy cùng nhìn vào bộ não của AI.
Giống như con người, bộ não của AI dự đoán cũng có neuron. Chúng được biểu thị dưới dạng các vòng tròn được liên kết với nhau.
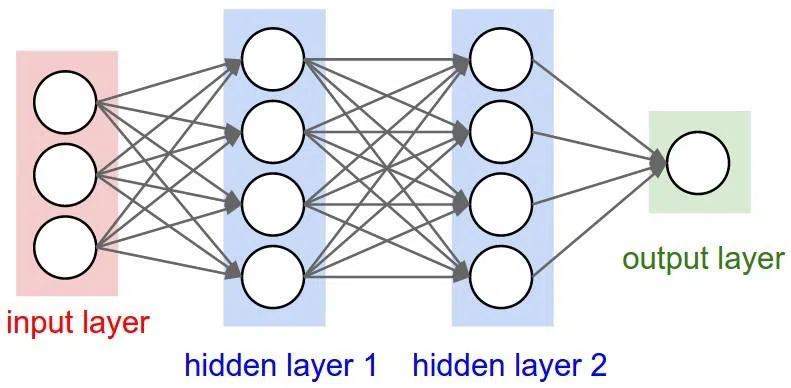
Các neuron được nhóm thành 3 loại lớp (layer) như sau:
- Input layer (lớp đầu vào)
- Hidden layer (s) (lớp ẩn)
- Output layer (lớp đầu ra)
Lớp đầu vào nhận dữ liệu đầu vào. Trong trường hợp trên, chúng ta có 4 neuron trong lớp này: Origin Airport, Destination Airport, Departure Date và Airline. Các đầu vào sẽ đi qua Input layer để đi vào lớp ẩn.
Lớp ẩn thực hiện các tính toán về mặt toán học đối với các đầu vào. Một trong những thử thách trong việc tạo được các mạng neuron đó là quyết định số lượng các lớp ẩn cũng như số neuron cho mỗi lớp.
Từ "Deep" trong Deep Learning ám chỉ có nhiều hơn một lớp ẩn.
Lớp đầu ra sẽ trả về các dữ liệu đầu ra. Trong trường hợp đang giả định đó là chúng ta sẽ nhận được thông tin về dự đoán giá.
Vậy thì AI tính toán giá dự đoán như thế nào?
Đây chính là điểm mà Deep Learning tạo ra điều kỳ diệu.
Mỗi một kết nối giữa các neuron được gắn với một trọng số (weight). Trọng số này quyết định tầm quan trọng của giá trị đầu vào. Ban đầu, các trọng số được đặt ngẫu nhiên.
Khi dự đoán giá vé máy bay, ngày khởi hành là một trong những yếu tố "nặng" nhất. Do đó, các kết nối neuron ở đầu vào ngày khởi hành sẽ có trọng số lớn.
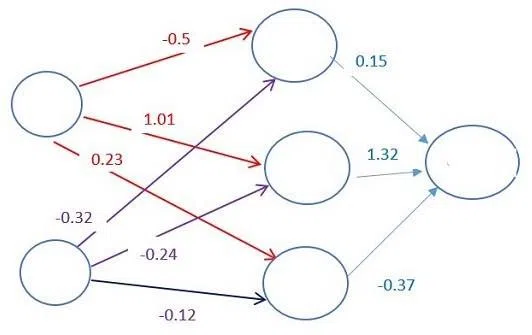
Mỗi neuron có một hàm kích hoạt (hàm f hay activation function). Các hàm này rất khó để hiểu nếu như không có kiến thức chuyên sâu về toán học.
Một cách đơn giản, một trong những mục đích của hàm kích hoạt đó là "chuẩn hóa" đầu ra từ neuron đầu vào.
Một khi một bộ dữ liệu đầu vào vượt qua tất cả các lớp trong mạng neuron thì nó sẽ trả lại dữ liệu đầu ra qua lớp đầu ra.
Không có gì phức tạp cả đúng không nào?
Đào tạo mạng Neuron nhân tạo
Dạy AI là phần khó nhất của Deep Learning. Tại sao?
- Bạn cần một bộ dữ liệu lớn.
- Bạn cần một lượng lớn sức mạnh điện toán.
Đối với AI dự đoán giá vé máy bay, chúng ta cần tìm dữ liệu lịch sử của các giá vé. Và vì một lượng lớn các kết hợp có thể giữa hãng máy bay và ngày khởi hành nên chúng ta cần một danh sách vô cùng lớn các giá máy bay.
Để dạy AI, chúng ta cần đưa cho nó dữ liệu đầu vào từ bộ dữ liệu của chúng ta và so sánh các dữ liệu đầu ra của nó với dữ liệu đầu ra từ bộ dữ liệu. Vì AI vẫn chưa được dạy nên đầu ra của nó sẽ không chính xác.
Một khi chúng ta nghiên cứu kỹ toàn bộ bộ dữ liệu, chúng ta có thể tạo ra một hàm cho thấy các dữ liệu đầu ra của AI khác với các dữ liệu thật sự như thế nào. Hàm này được gọi là hàm chi phí (Cost Function)
Một cách lý tưởng, chúng ta muốn hàm chi phí bằng 0, đồng nghĩa với đầu ra của AI giống với đầu ra của bộ dữ liệu.
Làm thế nào chúng ta có thể đạt được giá trị này?
Chúng ta thay đổi trọng số giữa các neuron. Chúng ta có thể ngẫu nhiên thay đổi chúng cho tới khi hàm chi phí thấp nhưng điều này không hề hiệu quả.
Thay vào đó, chúng ta sử dụng một kỹ thuật gọi là Gradient Descent.
Gradient Descent là một kỹ thuật cho phép chúng ta tìm điểm nhỏ nhất của một hàm. Trong trường hợp này, chúng ta đang tìm kiếm điểm nhỏ nhất của hàm chi phí.
Nó hoạt động bằng cách thay đổi trọng số với các lượng gia (increment) nhỏ sau mỗi lần lặp lại bộ dữ liệu. Bằng cách tính toán đạo hàm (hoặc gradient) của hàm chi phí ở một bộ trọng số cụ thể, chúng ta có thể nhìn thấy những hướng nào là nhỏ nhất.
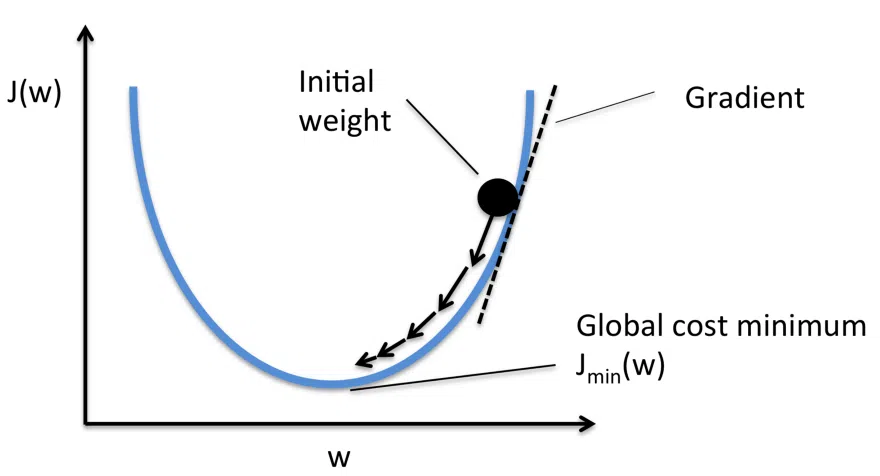
Để tối thiểu hóa hàm chi phí, chúng ta cần lặp lại bộ dữ liệu nhiều lần. Đó là lý do tại sao cần phải có lượng lớn sức mạnh điện toán.
Cập nhật trọng số bằng cách dùng Gradient Descent được thực hiện tự động. Đó là điều kỳ diệu của Deep Learning.
Một khi chúng ta dạy cho AI (dự đoán giá vé máy bay) thì chúng ta có thể sử dụng nó để dự đoán giá trong tương lai.
Bình luận