Các khái niệm cơ bản:
1. Document
Đơn vị thông tin nhỏ nhất trong ElasticSearch, lưu trữ thông tin về một đối tượng cụ thể. Document được lưu dưới dạng JSON. Document tương tự như table row trong relational database
Ví dụ một document lưu thông tin về Cristiano Ronaldo:
{
"_index": "football",
"_type": "_doc",
"_id": "SjddBWYBmm8m0dEKywPY",
"_version": 1,
"found": true,
"_source": {
"name": "Cristiano Ronaldo",
"age": 33,
"club": "Juventus"
}
}Hãy tạm thời bỏ qua các thuộc tính _index, _type, _version, found và chú ý vào 2 thuộc tính là _id và _source:
- _id: Mỗi document được gán một unique ID. Thuộc tính này giống như Primary Key trong relational database
- _source: Trỏ đến 1 JSON object; JSON object này gồm các trường lưu thông tin của đối tượng: name, age, club. Các trường trong JSON object này tương tự như table column trong relational database
2. Index
Một tập hợp các document. Các document này lưu trữ thông tin về một đối tượng, một chủ đề lớn
Ví dụ, một index Blog gồm 2 document, một document lưu thông tin bài viết, một document lưu thông tin tác giả:
{
"_index": "blog",
"_type": "_doc",
"_id": "Szd5BWYBmm8m0dEKDgP6",
"_version": 1,
"found": true,
"_source": {
"title": "Nhập môn Elastic search",
"content": "Blah blah blah...",
"category": "Database"
}
}
{
"_index": "blog",
"_type": "_doc",
"_id": "TDd6BWYBmm8m0dEKlgN_",
"_version": 1,
"found": true,
"_source": {
"author_name": "Mòe",
"age": 26,
"is_handsome": true
}
}3. Cluster & Node
Một Cluster là một tập hợp gồm nhiều Node, mỗi Node là một server lưu trữ các index.
Mỗi Node và Cluster được gán một Universal Unique ID (UUID). Một Node có thể join vào một Cluster dựa vào UUID của Cluster đó. Mỗi Node được tạo ra sẽ được join vào một Cluster mặc định là elasticsearch
4. Shard & Replica
Một Index có thể được chia ra thành nhiều Shard, mỗi Shard chứa một ít document của Index đó. Mỗi Shard của một Index có thể được đặt ở các Node khác nhau trong 1 Cluster.
Shard có thể được nhân bản để tạo thành một Replica. Replica có thể được đặt trong cùng 1 Node với Shard gốc, nhưng tốt nhất là đặt Replica ở một Node khác để đề phòng Node chứa Shard gốc chẳng may bị sập thì vẫn còn Replica ở Node kia
Lưu ý:
Trước đây ElasticSearch có một khái niệm là Type. Một Index có thể có nhiều Type, mỗi Type là một tập hợp các document có cùng 1 tính chất, ví dụ Index Blog có 2 Type: Type Post lưu các document liên quan đến bài viết, Type Author lưu các document liên quan đến tác giả. Type tương đương với tabletrong relational database.
Tuy nhiên, bắt đầu từ version 6, ElasticSearch đã bỏ khái niệm Type. Vấn đề này xin phép trình bày ở bài viết sau.
Hướng dẫn cài đặt ElasticSearch bằng Docker:
1. Kéo ElasticSearch Docker Image version 6.4.1
docker pull docker.elastic.co/elasticsearch/elasticsearch:6.4.1
2. Chạy lệnh Docker run
docker run -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:6.4.1
3. Check xem đã cài được chưa:
Dùng Postman và gửi một GET Request đến địa chỉ http://localhost:9200
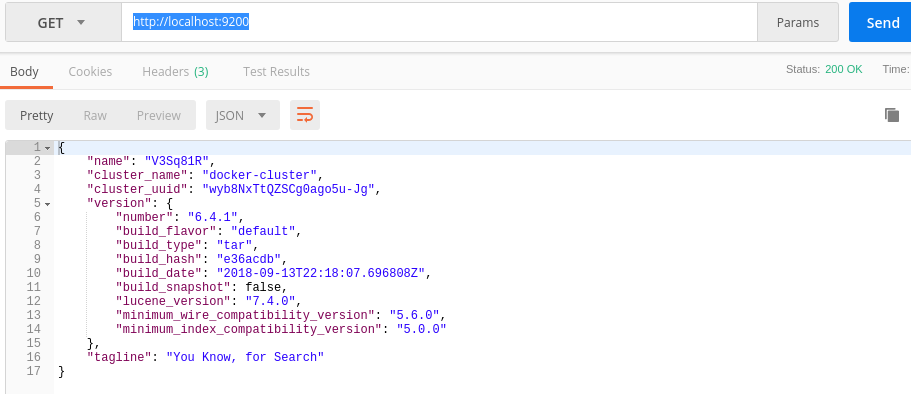
thu được kết quả trả về là một file JSON:
{
"name": "V3Sq81R",
"cluster_name": "docker-cluster",
"cluster_uuid": "wyb8NxTtQZSCg0ago5u-Jg",
"version": {
"number": "6.4.1",
"build_flavor": "default",
"build_type": "tar",
"build_hash": "e36acdb",
"build_date": "2018-09-13T22:18:07.696808Z",
"build_snapshot": false,
"lucene_version": "7.4.0",
"minimum_wire_compatibility_version": "5.6.0",
"minimum_index_compatibility_version": "5.0.0"
},
"tagline": "You Know, for Search"
}như vậy tức là cài được rồi
Nguồn tham khảo:
https://www.elastic.co/guide/en/elasticsearch/reference/current/_basic_concepts.html
Bình luận