Hôm trước mình có join 1 vụ webinar do Cloudera tổ chức: Racing for Results! Data Warehouse — Impala vs. Hive LLAP. Cơ bản là so sánh và đánh giá về 2 Query Engine là Impala và Hive LLAP xem cái nào phù hợp cho hệ thống DataWarehouse (DW), hôm nay có thời gian ngồi note lại các ý chính cho các bạn cùng theo dõi.
1. Quan viên hai họ.
Trước khi giới thiệu quan viên 2 họ thì phải điểm qua chút thông tin về 2 nhân vật chính. Impala trước đây thuộc nền tảng CDH của Cloudrea, bên kia chiến tuyến, Hortonwork có Hive và HiveLLAP như là 2 query engine đại diện 2 nền tảng. Tuy vậy kể từ khi sát nhập, đã có 1 số services bị loại bỏ nhưng với Hive và Impala, cả 2 đều được giữ lại, mỗi engine vẫn có những vai trò riêng. Sau khi hợp nhất CDH và HDP thành CDP, cả Hive và Impala vẫn đang tiếp tục được phát triển và cập nhật thêm các tính năng mới.
https://docs.cloudera.com/data-warehouse/1.0/release-notes/topics/dw-private-cloud-whats-new-01.html
Trong buổi hôm đó, đại diện nhà Impala là bác Justin Hayes, còn phía Hive là bác Bill Zhang, Bio 2 bác như bên dưới. 
2. Nhân vật chính
Như đã nói ở trên, hai nhân vật chính là 2 Query engine. Về độ phủ của 2 công nghệ này, trong buổi webinar có 2 khảo sát về thực thế sử dụng của chúng và đây là kết quả: 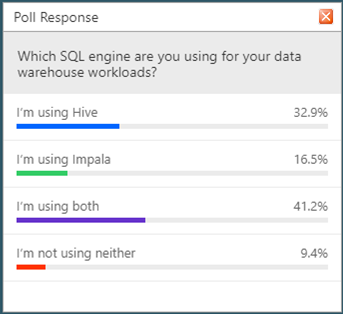
Ở poll đầu tiên, tỉ lệ sử dụng Hive cao hơn Impala, không rõ các ông dùng cả 2 thì có phải dùng Hive là chính Impala là phụ hay ngược lại không nhưng những con số nói lên Hive đang được sử dụng nhiều hơn. Có thể do ban đầu các tổ chức tiếp cận Hive thông qua nền tảng HDP và vẫn tiếp tục sử dụng nó cho đến ngày nay. Tuy nhiên không thể phủ nhận 1 điều là Hive là 1 query engine chịu tải tốt và ốn đinh. 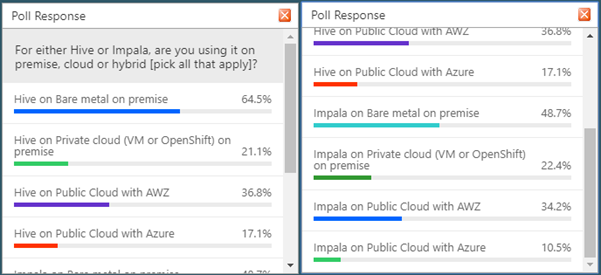
Về việc cài đặt triển khai, phần lớn cũng đang sử dụng trên nền tảng On-permise (có thể hiểu là tổ chức tự xây dựng phần cứng và triển khai services trên đó). Các nền tảng Cloud cũng đang ngày 1 phát triển nhưng do đối tượng khách hàng phần đông là các tổ chức doanh nghiệp nên việc đẩy dữ liệu lên Cloud cũng là 1 vấn đề tương đối phức tạp. Hy vọng với nhiều ưu điểm của hạ tầng Cloud như dễ dàng mở rộng hay thời gian triển khai dịch vụ rất nhanh, nó sẽ trở thành xu hướng cho các hệ thống Big Data.
3. Modern Data Warehouse
Trong kiến trúc DW hiện đại, việc lựa chọn 1 Query Engine phù hợp là vô cùng quan trọng, hãy xem hình sau: 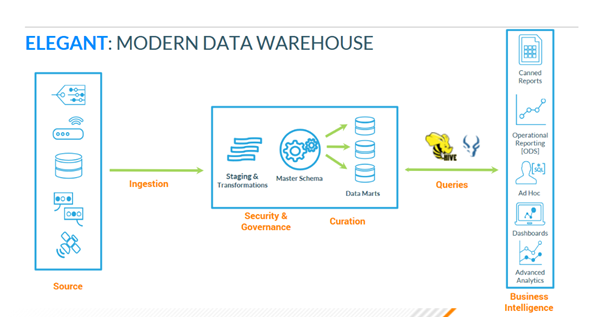
Có thể thấy, toàn bộ các công cụ bên ngoài, muốn giao tiếp với dữ liệu của hệ thống không còn con đường nào khác là thông qua Query Engine.
Thông thường, các query vào DW có thể được chia làm 2 loại:
- Aggregation Query (Heavy Workload): Sử dụng Query Engine thực hiện các câu lệnh SQL để tổng hợp dữ liệu. VD như dữ liệu chi tiết giao dịch của cả 1 ngày được tổng hợp lại theo từng khách hàng hay loại sản phẩm, hay phải join nhiều bảng với nhau… Đây là loại query nặng, có thể chạy hàng giờ đồng hồ. Yêu cầu quan trọng cho loại tính toán này là Query Engine phải chịu tải, chịu lỗi tốt, nhanh chậm 1 chút cũng không thành vấn đề.
- Interactive Query: Sau khi dữ liệu được tổng hợp, khi cần khai thác lên báo cáo hoặc phân tích. Lọai query này không nặng, thường chỉ là select sau đó sum hoặc group by theo 1 số điều kiện nhất định. Tuy nhiên loại này lại cần tốc độ cao. Không khách hàng nào muốn load 1 cái báo cáo hết vài phút cả. Query Engine loại này cần nhanh, chịu được nhiều truy vấn đồng thời.
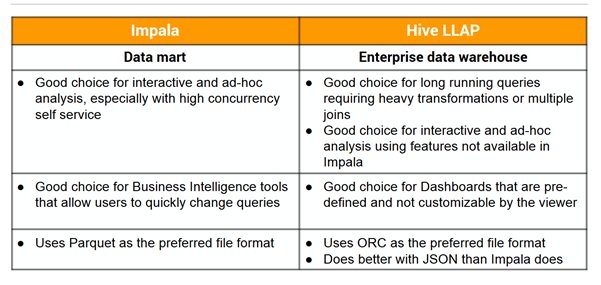
Đây là phần kết quả rút ra được sau buổi tranh luận.
Về Impala:
- Phù hợp cho Data Mart (tập nhỏ của DW, phục vụ cho 1 đơn vị cụ thể).
- Phục vụ tốt cho Interative, ad-hoc query với nhiều truy vấn đồng thời.
- Thường sử dụng cho các công cụ BI có sự thay đổi truy vấn thường xuyên.
- Preferred format là Parquet
Hive LLAP:
- Phù hợp cho query nặng (thường để tổng hợp dữ liệu).
- Cũng có thể dùng cho interactive hoặc ad-hoc query sử dụng những functions mà Impala không có.
- Cũng có thể dùng cho interactive hoặc ad-hoc query sử dụng những functions mà Impala không có.
- Preferred format là ORC.
Ba ý đầu, mình nghĩ đã khá clear nếu bạn đọc bài của mình từ đầu. Còn ý cuối cùng về format file, thực ra Hive cũng có thể làm việc tốt với Parquet hay Impala cũng có thể đọc được ORC.
Có 1 bài viết trên medium benchmark 2 loại file này và có rút ra kết luận rằng: ORC thì tốt cho việc lưu trữ dữ liệu (tạo file nhanh, dung lượng nhỏ hơn so với Parquet) nhưng để tối ưu cho việc đọc thì hãy dùng Parquet (truy vấn rất nhanh).

Vì vậy nếu có cân nhắc giữa 2 định dạng này và 2 Query Engine, các bạn hoàn toàn có thể mix nhau để tận dụng lợi thể của cả Engine và file-format. VD bên mình đang dùng Hive với Parquet rất ổn
Link bài viết gốc tại đây
Bài viết đăng tải lại dưới sự cho phép của tác giả : thầy Nguyễn Chí Thanh là giảng viên khoá Big Data tại Techmaster
Bình luận