
Hi các bạn, trong bài trước mình đã nói về các tính năng mới của Spark 3.0, một trong những nâng cấp quan trọng ở phiên bản này là Adaptive Query Execution (AQE).
Như các mọi người đã biết, Spark SQL luôn có hiệu năng rất tốt, một trong những lý do để có được điều này là do SparkSQL có module tối ưu thực thi Catalyst Optimizer. Mình cũng đã viết 1 bài về chủ đề này, các bạn có thể đọc lại ở đây.
Ở Spark 1.x, ta có Rule-based optimizer, Spark 2.x là sự kết hợp giữa cả Rule-based và Cost-based optimizer. Tuy nhiên thực tế vẫn còn 1 số hạn chế chưa được giải quyết: 
- Việc collect các thông tin statistics phục vụ input cho optimizer có cost lớn, đặc biệt với các câu lệnh phức tạp.
- Thông tin statistics có thể bị sai, VD với file nén, lúc estimate có dung lượng X nhưng khi compute thực tế lại là dung lượng Y hoặc trong hệ thống phức tạp hay với các hàm UDF (do người dùng định nghĩa).
Với AQE, Spark 3.0 sẽ thực hiện tối ưu và thay đổi plan ngay lúc runtime. Bao gồm
- Chuyển đổi Sort Merge Join sang Broadcast Hash Join linh hoạt.
- Hiệu chỉnh số reduces theo ngữ cảnh dữ liệu thực tế.
- Kiểm soát được Skew join tự động
Ok, hãy bắt đầu với từng tính năng nhé.
Convert Sort Merge Join to Broadcast Hash Join
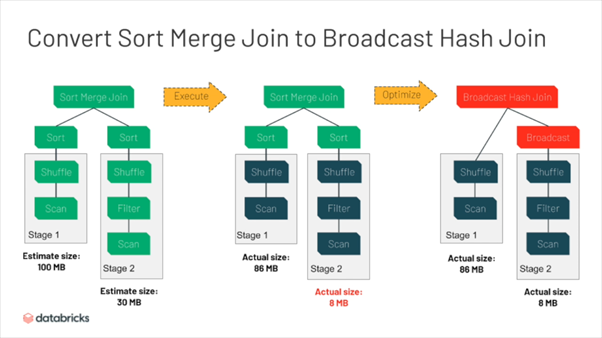
Nếu đã làm việc nhiều với Spark, bạn có thể biết rằng khi join 2 bảng dữ liệu, Broad cast join trong hầu hết trường hợp đều có thời gian thực hiện nhanh hơn (nếu chưa rõ, hãy đọc lại bài về Join trong Spark của mình ở đây). Tuy nhiên nó lại chỉ phù hợp với bảng có kích thước nhỏ, trước đây ta có thể điều chỉnh kích thước của tập dữ liệu “thế nào là nhỏ” thông qua cấu hình: spark.sql.autoBroadcastJoinThreshold
Trong trường hợp join 2 bảng, giá trị estimate dữ liệu của 1 bảng lớn hơn ngưỡng broadcast join, Spark mặc định sử dụng Sort Merge Join, tuy nhiên giá trị estimate này có thể không đúng (VD dữ liệu bảng là nén). Với AQE, spark có thể thay đổi về Broadcast join trong lúc runtime nếu dung lượng thực tế vẫn trong ngưỡng sử dụng Broadcast join.
Dynamically Coalesce Shuffle Partitions
Một vấn đề khác của Spark là việc bị fix bởi 1 số default parallelism (=200). Dẫn tới việc không có sự thay đổi linh hoạt số reducers giữa các stage. VD dữ liệu đầu vào lớn, sau đó qua 1 vài bước tổng hơp, dữ liệu output còn lại nhỏ hơn nhưng số reducers vẫn không đổi. Spark 3 đã khắc phục được vấn đề này với giải pháp tự động coalesce thông minh giữa các stage, giúp tối ưu số reducers cho toàn bộ quá trình thực thi. 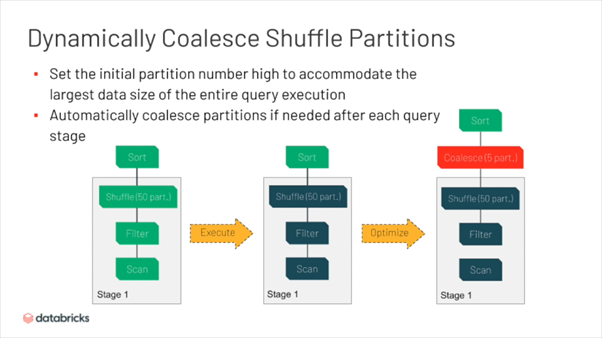
Như trên hình, có thể thấy với output 50 partitions, lượng dữ liệu đủ nhỏ, Spark có thể chủ động coalesce dữ liệu trước khi đến bước sort, giúp tiết kiệm 45 task dư thừa.
Handle skew join
Nói qua về Data Skew cho bạn nào chưa biết, nó là hiện tượng 1 task nào đó phải xử lý nhiều dữ liệu hơn hẳn các task khác. Đặc biệt với các thao tác xử lý theo key như join, nếu trong tập dữ liệu của bạn có 1 hoặc 1 vài key có số lượng bản ghi nhiều gấp nhiều lần các key khác (hay gặp là key null) thì xin chia buồn , dữ liệu của bạn đã bị skew 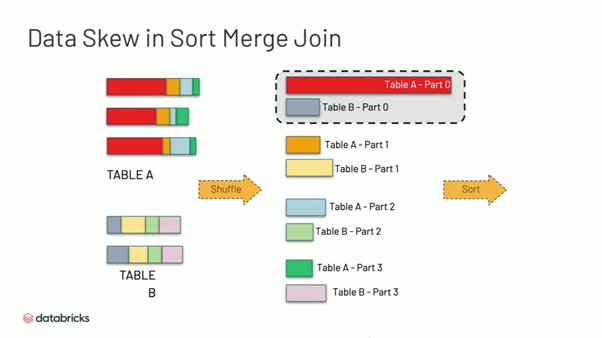
AQE trong Spark 3 còn có thể giải quyết vấn đề skew join hoàn toàn tự động. Trước đây, nếu có việc lệch key giữa các bảng trong lúc join, thông thường phải loại bỏ key skew để xử lý đặc biệt hoặc sử dụng kỹ thuật Salt để tách key thành các sub-key.
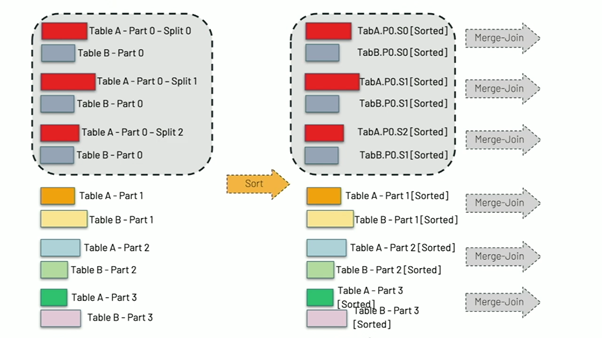
Tuy nhiên, ở phiên bản mới, AQE tự động nhận biết dữ liệu lệch và tự chia dữ liệu thành các phần nhỏ hơn để phù hợp với workload 1 task.
Spark sử dụng Skew Reader để chia dữ liệu thành các phần nhỏ. 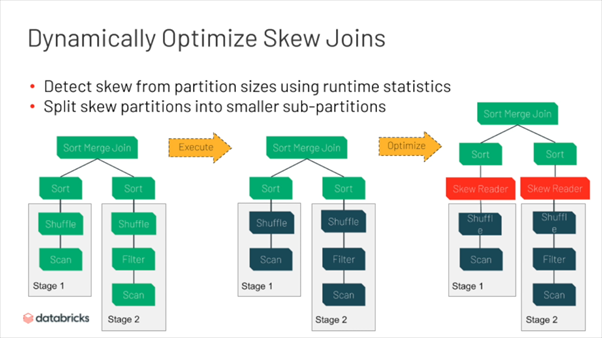
Với dữ liệu cần join với phần dữ liệu skew, spark sẽ duplicate và gửi đến các sub-partition để đảm bảo logic chính xác. 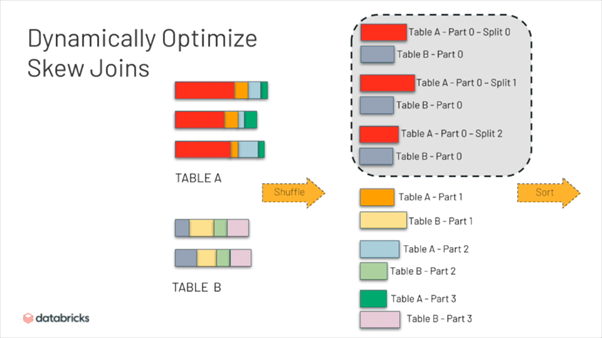
AQE Essential configuration Settings
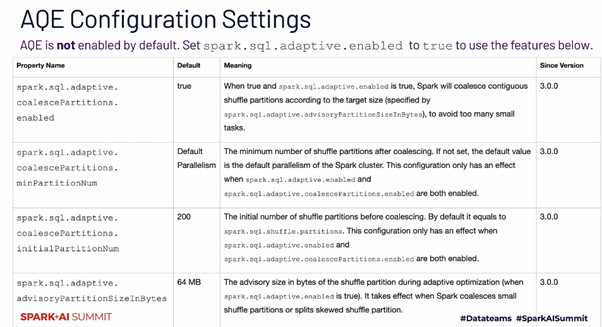
1 điểm cần lưu ý là mặc định Spark 3.0 sẽ không enable AQE, bạn buộc phải cấu hình sử dụng AQE thông qua config: spark.sql.adaptive.enabled = true
Link bài viết gốc tại đây
Bài viết đăng tải lại dưới sự cho phép của tác giả : thầy Nguyễn Chí Thanh là giảng viên khoá Big Data tại Techmaster
Bình luận