Sau 4 phần, chắc mọi người cũng đã có những cái nhìn chi tiết hơn về mô hình, kiến trúc và các thành phần quan trọng của Spark rồi, bài hôm nay sẽ đi chi tiết vào 1 phần mình nghĩ là thú vị hơn. Sẽ không còn là lý thuyết mô hình nữa, hãy cùng xem các API và functions quan trọng trong Spark SQL nhé. 
Tại sao nhỉ, nói đi nói lại thì Spark là 1 thư viện, và cách tốt nhất để hiểu nó là tương tác qua những dòng code.
Bắt đầu nhé!
1. Environment
Ngoài việc tự triển khai Spark trên môi trường thật hoặc local, các bạn có thể sử dụng Notebook free của Databricks để thực hành. Việc này vừa giúp dễ dàng thực hiện code và lưu lại công việc, vừa không mất công tìm hiểu cài đặt triển khai vốn khá phức tạp.
Link đăng ký tài khoản ở đây.
https://community.cloud.databricks.com/
Sau khi tạo tài khoản đầu tiên hãy tạo 1 cluser mới, cluster là phần phía sau thực thi code Spark cho chúng ta, giao diện rất đơn giản, nhập tên cluster và nhấn Create Cluster, chờ 1 lát để cluster hoàn tất khởi động.
Tất cả đều thông qua trình duyệt web nên rất dễ dàng tiếp cận kể cả với các bạn có máy tính cấu hình không cao. Tuy cấu hình cluster không quá lớn nhưng là đủ cho việc thử nghiệm và nghiên cứu về Spark. 
Tiếp đến hãy tạo 1 Notebook, đây giống như là Editor, nơi chứa code, giúp ta thực thi các hàm và hiển thị kết quả. 
2. DataFrame & DF Operations
Ok vậy là xong, đã có cluster và notebook đã sẵn sàng, tuy nhiên mình sẽ nhắc nhanh lại 1 chút kiến thức về DF, chi tiết các bạn đọc lại phần 3 nhé. 
1 số các Operation với DF quan trọng mình đã note lại ở hình sau, bài hôm nay chúng ra sẽ thực hành một trong số operations này nhé: 
3. Try out SparkSQL and DataFrame
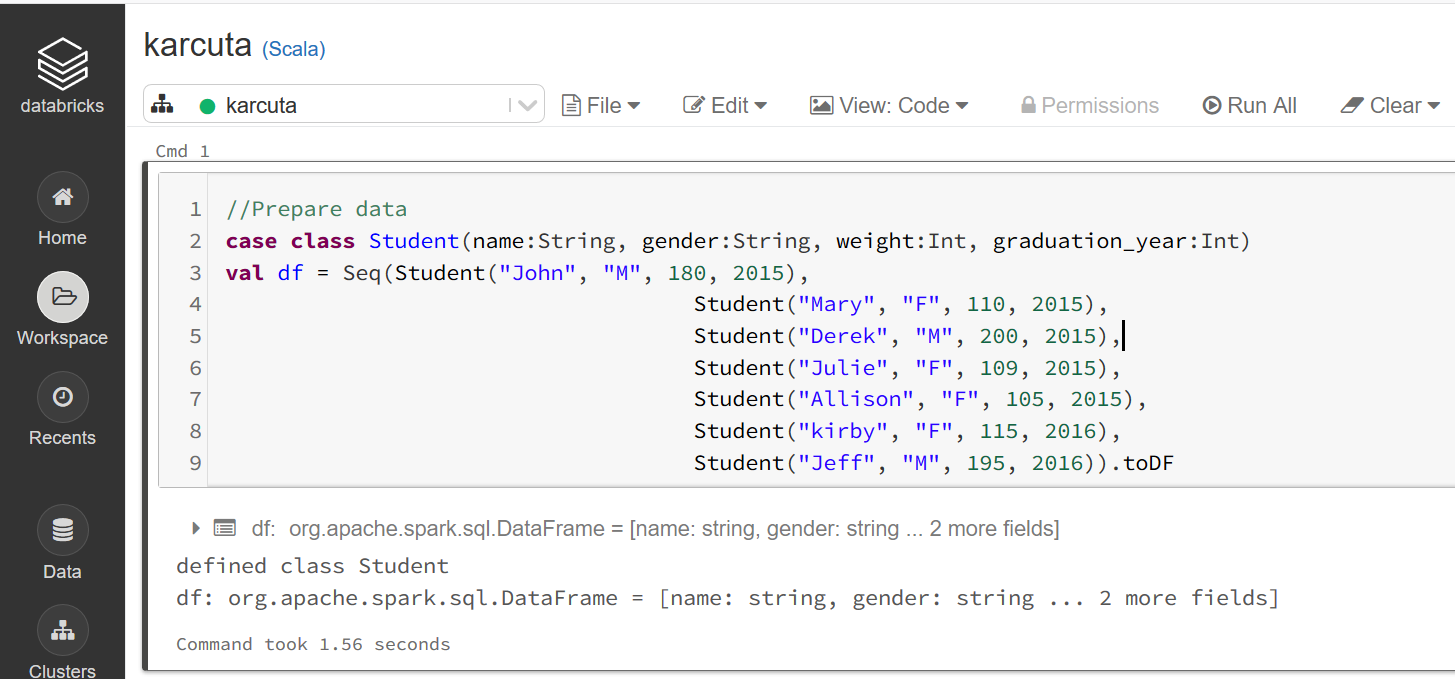
Bắt đầu nhé, trong notebook, sử dụng đoạn code sau để tạo dữ liệu sample, ở đây mình tạo 1 DF có 4 trường name, gender, weight, graduation_year với 7 bản ghi:
//Prepare datacase class Student(name:String, gender:String, weight:Int, graduation_year:Int)
val df = Seq(Student("John", "M", 180, 2015), Student("Mary", "F", 110, 2015), Student("Derek", "M", 200, 2015), Student("Julie", "F", 109, 2015), Student("Allison", "F", 105, 2015), Student("kirby", "F", 115, 2016), Student("Jeff", "M", 195, 2016)).toDF
.show()
Thử show dữ liệu DataFrame vừa tạo ra nhé: 
Như đã thấy, do df chỉ có 7 bản ghi nên sẽ show toàn bộ, nếu tập dữ liệu lớn, chỉ 20 bản ghi đc hiển thị, bạn có thể truyền thêm số bản ghi cần hiển thị ở hàm show() nếu muốn thay đổi.
.printSchema()
Như 1 bảng dữ liệu, DataFrame cũng có schema, đại diện là 1 object StructType, schema chứa thông tin về tên trường và kiểu dữ liệu tương ứng. Trong ví dụ, do dữ liệu của df được convert từ các bản ghi của object Student nên đã có sẵn schema, với các loại dữ liệu input khác nhau, spark có thêm thuộc tính chỉ định schema (VD như dữ liệu text, csv, json) 
.collect()
Hãy nhìn lại chút về đoạn code trên, trông có vẻ đơn giản thôi chứ khi df được tạo, các dữ liệu về Student đã được phân tán sang nhiều node khác nhau, nếu muốn “kéo” dữ liệu từ các máy kia về, bạn dùng hàm collect() 
Để ý nhé, df và df.collect đều là tập 7 bản ghi nhưng khi chưa collect, trong code scala của bạn sẽ không có cách nào truy cập được bản ghi thứ 2 của tập này cả, vì theo logic nó không còn nằm trên máy bạn nữa, lúc này chương trình mà bạn đang code gọi là driver, các worker chứa dữ liệu phân tán và thực thi tính toán gọi là executor.
Khi collect() ta có 1 Array thông thường và có thể làm mọi thứ như mọi Array khác như foreach(), map()…
Nói ngắn gọn hơn, dữ liệu của df lưu trên executor và hàm collect sẽ lấy toàn bộ dữ liệu từ executor về driver.
.rdd()
Được xây dựng dựa trên Spark core, nếu bạn đã quen thuộc với các api của RDD, DataFrame có thuộc tính .rdd để truy cập vào dữ liệu như 1 RDD, khi đó bạn có thể call các api của RDD. 
Bản thân DF không có partitions nên muốn biết DF có bao nhiêu partitions, ta gọi qua RDD của nó. Như trên có thể thấy có 7 bản ghi với 7 partitions, tức là mỗi bản ghi lại phân tán trên 1 nơi khác nhau.
Hãy thử tạo 1 Cluster với Databrick platform và thử các operations còn lại của DF mà mình đã giới thiệu bên trên nhé
Link bài viết gốc tại đây
Bài viết đăng tải lại dưới sự cho phép của tác giả : thầy Nguyễn Chí Thanh là giảng viên khoá Big Data tại Techmaster
Bình luận