1. Spark Catalyst Optimizer
Như các bạn đã biết, Spark SQL có 2 thành phần chính:
- DataFrame API, cung cấp các hàm hỗ trợ tính toán và xử lý dữ liệu có cấu trúc phân tán.
- Catalyst Optimizer: Bộ tối ưu thực thi.
Trong hầu hết các bài test, Spark SQL luôn có hiệu năng rất tốt, một trong những lý do để có được điều này là do SparkSQL có module tối ưu thực thi Catalyst Optimizer.
Khi làm việc với lượng lớn dữ liệu, hãy nghĩ đến hàng tỉ bản ghi, nếu việc tính toán có n bước dư thừa, nó sẽ là sự dư thừa của n tỉ tính toán. Việc code chưa tối ưu tồn tại mọi nơi chứ không riêng gì với các hệ thống dữ liệu lớn, nhưng ảnh hưởng của nó lên hệ thống lớn đáng kể hơn nhiều, và Catalyst Optimizer sẽ như một bước bảo đảm sẽ loại bỏ bớt sự chưa tối ưu đó 1 cách chủ động, thông qua tập rule-base và cost-base được xây dựng sẵn.
Như hình trên có thể thấy, Catalyst Optimizer đóng vai trò trung gian, một bên là code của người dùng, các tương tác đọc/ ghi/ tính toán với dữ liệu thông qua DataFrame API, một bên là những gì sẽ được thực thi trên các executor.
Nói ngắn gọn, Catalyst Optimizer có thể sẽ “chỉnh sửa lại” code của bạn trước khi thực thi đảm bảo việc tính toán hiệu quả nhất mà vẫn đảm bảo kết quả như bạn mong muốn.
Để dễ hình dùng, hãy cùng phân tích câu lệnh sau:
Có 2 điều cần nói ở đây:
- Giả sử câu lệnh chạy trên bảng t1 chứa 1 tỉ bản ghi, theo thông thường, phép tính 1+2 sẽ được thực hiện đi thực hiện lại 1 tỉ lần.
- Giả sử bảng t2 cũng có 1 tỉ bản ghi nhưng chỉ có 100 bản ghi thỏa mãn điều kiện t2.id>50*1000. Lẽ nào vẫn phải join full sau đó lại lọc 900k kết quả không thỏa mãn?
Catalyst Optimizer được sinh ra để đảm bảo rằng Spark sẽ không thực hiện những tính toán dư thừa kia, cho dù bạn có muốn hay không.
Với câu lệnh trên, ta có thể tính trước giá trị 1+2 =3, sau đó chỉ cần lấy t1.value + với 3, chỉ như như vậy đã tiết kiệm được 1 tỉ lần phép tính vô nghĩa 1+2 mà hoàn toàn không làm sai lệch kết quả. Còn với phép so sánh, có thể lọc 100k bản ghi của t2 thỏa mãn trước khi join, sẽ tiết kiệm được rất nhiều thời gian shuffle 900k bản ghi dư thừa qua lại giữa các executor.
2. Execution Plan
Catalyst Optimizer chia thành nhiều giai đoạn, qua mỗi bước sẽ hoàn thiện dần plan thực thi từ Logical Plan (logic thực thi theo code của bạn) cho đến Physical plan (những gì sẽ thực tế được gửi đi đến executor để tính toán).
Với ví dụ câu lệnh ở trên Query Plan sẽ như hình bên dưới:
Đúng như mình đã trình bày, logic thực hiện (đọc từ dưới lên trên) sẽ là: Đọc 2 bảng t1 và t2, join với nhau, lọc các bản ghi theo điều kiện, chọn các trường cần tính toán và thực hiện sum rồi trả về kết quả.
Rõ ràng plan này hoàn toàn chưa tối ưu, sau khi qua Catalyst Optimizer, ta có 1 plan thực thi như sau:
Việc lọc dữ liệu được rẽ nhánh ngay sau bước đọc dữ liệu bảng t2, lúc này việc join sẽ chỉ quan tâm đến việc match key giữa 2 bảng với số lượng bản ghi ở bảng 2 đã lọc bỏ các bản ghi không thỏa mãn điều kiện. Plan này chính là những gì sẽ được chạy thực tế trên các executor. Có thể hơi khác với những gì bạn code nhưng nó hoàn toàn đảm bảo kết quả và rút ngắn thời gian thực thi.
Catalyst Optimizer chỉ có ở Spark SQL, nếu bạn sử dụng RDD API (Spark Core), sẽ không có quá trình tối ưu nào diễn ra và nếu code không tốt, các bước dư thừa vẫn sẽ được thực thi, vì vậy trong mọi trường hơp có thể, hãy sử dụng Spark SQL để được hưởng lợi từ những gì mà Catalyst Optimizer đem lại. Bộ Analyzer của Catalyst Optimizer rất dài và cover được hầu hết các case, chi tiết bạn có thể xem code ở đây.
3. Demo
Hãy thử trải nghiệm 1 ví dụ đơn giản nữa để xem Catalyst Optimizer hoạt động thế nào nhé. 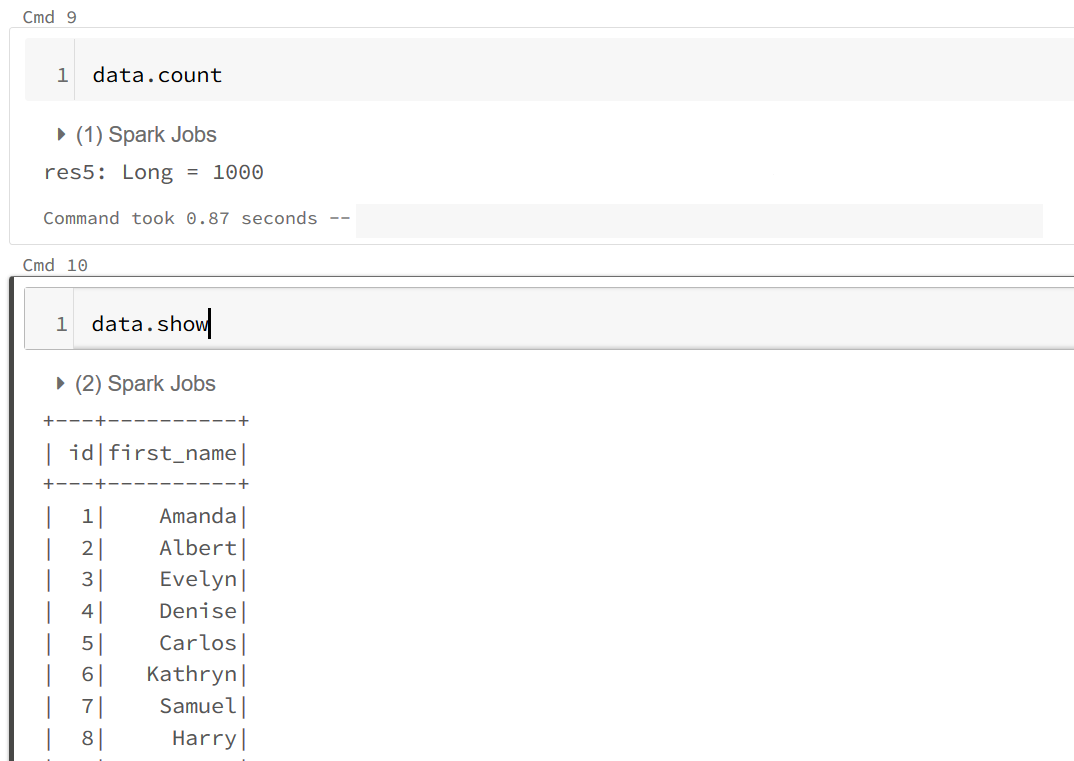
Đầu tiên, mình tạo 1 DataFrame có 1000 bản ghi, sau đó sẽ chuyển first_name thành chữ viết hoa và đếm số lượng bản ghi của df này. 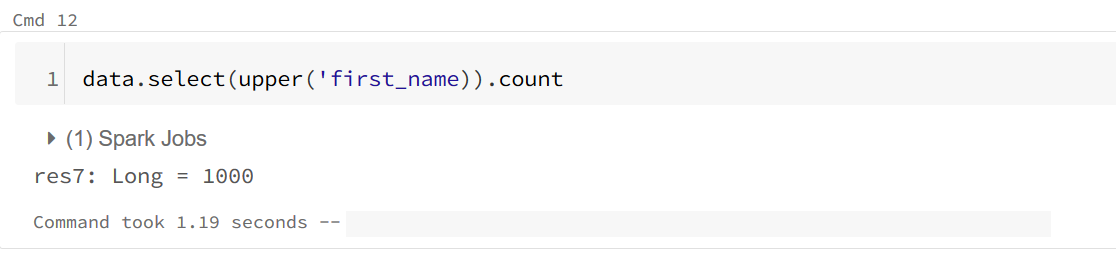
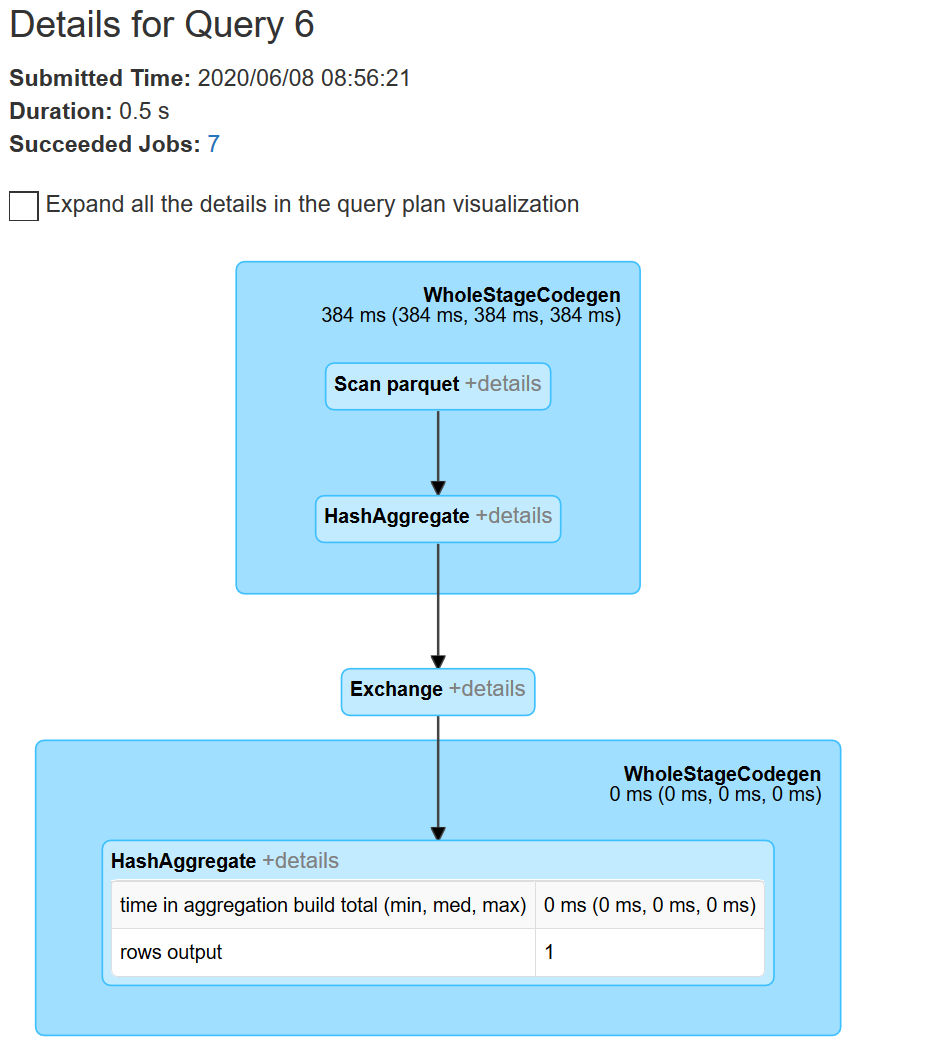
Đây là những gì đã thực sự được thực hiện, hoàn toàn không thấy đoạn công việc upper first_name ở đâu??? (các bạn có thể xem DAG tại tab SQL trên Spak UI)
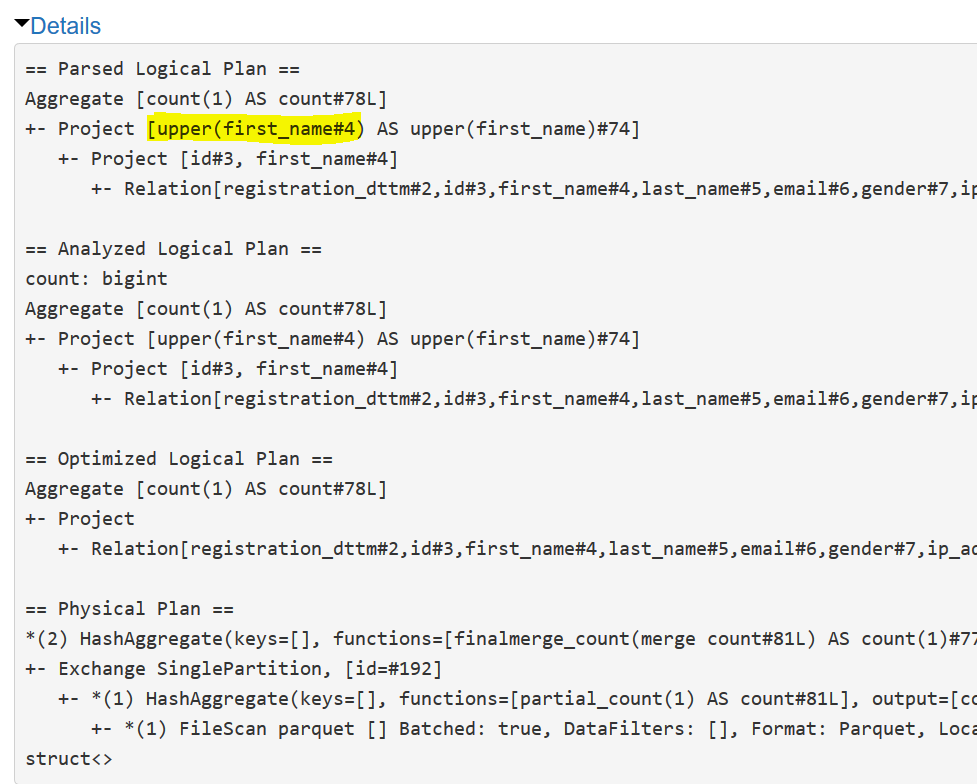
Tất nhiên không phải mình submit code thiếu, nếu nhìn vào details các plan được sinh ra, ở phase đầu tiên, việc upper first_name đã xuất hiện ở Parsed Logical Plan, tuy nhiên Catalyst Optimizer hiểu rằng trong trường hợp này, có upper hay làm gì đi chăng nữa thì số lượng bản ghi cũng không đổi và nó quyết định sẽ không upper first_name. Ở đây có thể nói rằng Catalyst Optimizer đã “sửa lại” code của chúng ra.
Trên đây là các ví dụ đơn giản để các bạn hiểu hơn về Catalyst Optimizer, nếu trong 1 câu lệnh phức tạp, các tính toán dư thừa nằm ẩn sau các câu lệnh lồng ghép thì không dễ để tối ưu lại. May mắn là Spark SQL đã được trang bị bộ Catalyst Optimizer rất mạnh mẽ phải không nào
Link gốc bài viết tại đây
Bài viết đăng tải lại dưới sự cho phép của tác giả : thầy Nguyễn Chí Thanh là giảng viên khoá Big Data tại Techmaster
Bình luận