Bài viết gốc: https://medium.freecodecamp.org/how-to-implement-a-simple-hash-table-in-javascript-cb3b9c1f2997
Tác giả: Alex Nadalin.
Dịch giả: Togahepi a.k.a Hà Hiệp.
Bạn có thấy dấu {} đẹp tuyệt vời không?
Nó cho phép bạn lưu dữ liệu tương ứng với khóa, và truy xuất lại vô cùng dễ dàng (O(1), chúng ta sẽ bàn tới ở sau).
Trong bài viết này tôi sẽ hướng dẫn cách triển khai một hash table đơn giản, chúng ta sẽ mổ sẻ cách nó hoạt động để hiểu sâu hơn về một trong những ý tưởng siêu phàm trong khoa học máy tính.
Vấn đề
Tưởng tượng rằng bạn đang xây dựng một ngôn ngữ lập trình mới: bạn sẽ bắt đầu bằng những kiểu dữ liệu đơn giản (chuỗi, số nguyên, số thập phân, ...) và rồi sẽ xây dựng những cấu trúc dữ liệu đơn giản. Đầu tiên bạn có mảng array ([ ]), rồi sẽ tới hash table (hay được biết đến như từ điển, mảng liên kết, hashmap, map và ... còn dài lắm).
Có bao giờ bạn tự hỏi chúng hoạt động ra sao? Như thế nào mà chúng lại hoạt động nhanh như cắt vậy?
Ta sẽ giả sử như JavaScript không có { } hoặc new Map (), và ta sẽ tự xây dựng phiên bản tự chế DumbMap - NguNgơMap!
Ghi chú về độ phức tạp của thuật toán
Trước khi chúng ta tiến hành, các bạn nên hiểu độ phức tạp thuật toán của một hàm là gì: Wikipedia có định nghĩa rõ ràng tại đây độ phức tạp thuật toán, nhưng tôi sẽ giải thích một cách vắn tắt cho mấy nàng lười luôn.
Độ phức tạp đo lường bao nhiêu bước cần phải thực hiện trong hàm - càng ít bước thì sẽ càng chạy nhanh (tên gọi khác là "running time" càng ngắn càng ngon).
Bây giờ hãy nhìn vào hàm này:
function fn(n, m) {
return n * m
}Độ phức tạp thuật toán (gọi tắt luôn là "độ phức tạp") của hàm fn là O(1), nghĩa nó là hằng số (bạn có thể gọi O(1) là "tốn có một"): bất kể tham số đầu vào của bạn lớn như thế nào thì hàm này sẽ chỉ chạy một phép tính (nhân n với m). Do nó chỉ tốn một phép tính nên độ phức tạp chỉ là O(1).
Độ phức tạp được đo lường bởi đầu vào của hàm có thể rất lớn. Hãy nhìn vào ví dụ dưới dây:
function fn(n, m) {
let s = 0
for (i = 0; i < 3; i++) {
s += n * m
}
return s
}Bạn sẽ nghĩ rằng độ phức tạp sẽ là O(3)?
Do trong một số trường hợp độ phức tạp vô cùng lớn, vì vậy chúng ta sẽ "bỏ qua" những hằng số và coi O(3) cũng bằng O(1). Vì thế, trong trường hợp này thì độ phức tạp của hàm fn cũng là O(1). Bất kể n, m như thế nào thì bạn cũng chỉ tính toán có 3 phép tính - là một hằng số (vì thế vẫn chỉ là O(1)).
Bây giờ hãy xem một ví dụ khác biệt chút xíu:
function fn(n, m) {
let s = []
for (i = 0; i < n; i++) {
s.push(m)
}
return s
}Bạn thấy đó, chúng ta sẽ lặp lại n lần, vì thế n có thể lên tới hàng triệu lần. Trong trường hợp này, chúng ta định nghĩa độ phức tạp của hàm này là O(n), vì bạn sẽ phải thực hiện số phép tính bằng với giá trị của tham số nhập vào.
Ví dụ khác nè?
function fn(n, m) {
let s = []
for (i = 0; i < 2 * n; i++) {
s.push(m)
}
return s
}Trong ví dụ này chúng ta sẽ lặp 2*n lần, nghĩa là độ phức tạp sẽ là O(2n). Tuy nhiên như ta đã nói từ trước những hằng số sẽ được "bỏ qua" khi tính toán độ phức tạp của hàm, vì thế trong ví dụ này độ phức tạp chỉ là O(n).
Thêm ví dụ nữa cho hiểu kĩ nè!
function fn(n, m) {
let s = []
for (i = 0; i < n; i++) {
for (i = 0; i < n; i++) {
s.push(m)
}
}
return s
}Ở đây chúng ta lặp lại n lần rồi trong mỗi lần chúng ta lại lặp n lần nữa như vậy độ phức tạp sẽ là "bình phương" n*n: nếu n là 2 thì chạy 4 lần, nếu là 3 thì chạy 9 lần, v.v.
Trong trường hợp này thì độ phức tạp sẽ được tính là O(n2) .
Chốt quả cuối cho chắc nè! :))
function fn(n, m) {
let s = []
for (i = 0; i < n; i++) {
s.push(n)
}
for (i = 0; i < m; i++) {
s.push(m)
}
return s
}Trong ví dụ này chúng ta không lồng các vòng lặp, mà chỉ lặp 2 vòng với 2 tham số: độ phức tạp sẽ là O(n+m). Rõ như ban ngày rùi.
Vậy là chúng ta đã có một màn giới thiệu nho nhỏ về độ phức tạp, nhờ đó ta hiểu một hàm với độ phức tạp O(1) sẽ chạy nhanh hơn nhiều so với hàm có độ phức tạp O(n).
Hash table có độ phức tạp là O(1): nhìn qua thì chúng sẽ rất là nhanh. Hãy đọc tiếp nhé.
(Tôi hơi có chém khi nói hash table luôn luôn có độ phức tạp là O(1), nhưng hãy cứ đọc tiếp nhé ;))
Hãy xây dựng một hash table (phiên bản ngu ngơ)
Hash table của chúng ta sẽ có 2 phương thức - set(x, y) và get(x). Hãy bắt đầu nào:
class DumbMap {
get(x) {
console.log(`get ${x}`)
}
set(x, y) {
console.log(`set ${x} to ${y}`)
}
}
let m = new DumbMap()
m.set('a', 1) // "set a to 1"
m.get('a') // "get a"Chúng ta sẽ xây dựng một cách vô cùng đơn giản mà hiệu quả để lưu trữ cặp chìa khóa-giá trị (key-value) và có thể truy xuất tới chúng về sau. Đầu tiên ta sẽ lưu chúng vào một mảng (nhớ nhé, chúng ta không thể dùng { } bởi chúng ta đang xây dựng { } nhé - khủng khiếp chưa! :v):
class DumbMap {
constructor() {
this.list = []
}
...
set(x, y) {
this.list.push([x, y])
}
}Và để lấy phần tử ta muốn từ danh sách này thì cách đơn giản là:
get(x) {
let result
this.list.forEach(pairs => {
if (pairs[0] === x) {
result = pairs[1]
}
})
return result
}Ví dụ đầy đủ:
class DumbMap {
constructor() {
this.list = []
}
get(x) {
let result
this.list.forEach(pairs => {
if (pairs[0] === x) {
result = pairs[1]
}
})
return result
}
set(x, y) {
this.list.push([x, y])
}
}
let m = new DumbMap()
m.set('a', 1)
console.log(m.get('a')) // 1
console.log(m.get('I_DONT_EXIST')) // undefined
Hàm DumbMap của chúng ta tuyệt nhỉ! Làm việc chuẩn chỉ luôn, nhưng sẽ ra sao nếu ta cần thêm vào một lượng lớn cặp key-value?
Hãy benchmark một chút. Đầu tiên chúng ta sẽ thử tìm kiếm một phần tử không có mặt trong một hash table nhỏ với vài phần tử, sau đó sẽ thử với cái có lượng lớn phần tử sau:
let m = new DumbMap()
m.set('x', 1)
m.set('y', 2)
console.time('với một vài bản ghi trong map')
m.get('I_DONT_EXIST')
console.timeEnd('với một vài bản ghi trong map')
m = new DumbMap()
for (x = 0; x < 1000000; x++) {
m.set(`element${x}`, x)
}
console.time('với nhiều nhiều bản ghi trong map')
m.get('I_DONT_EXIST')
console.timeEnd('với nhiều nhiều bản ghi trong map')Kết quả? Không ngon nghẻ gì:
với một vài bản ghi trong map: 0.118ms
với nhiều nhiều bản ghi trong map: 14.412msVới cách triển khai của chúng ta, ta phải lặp qua tất cả các phần tử trong this.list để tìm một phần tử trùng với key. Độ phức tạp sẽ là O(n), khá là tệ nhỉ.
Làm nó nhanh hơn nào.
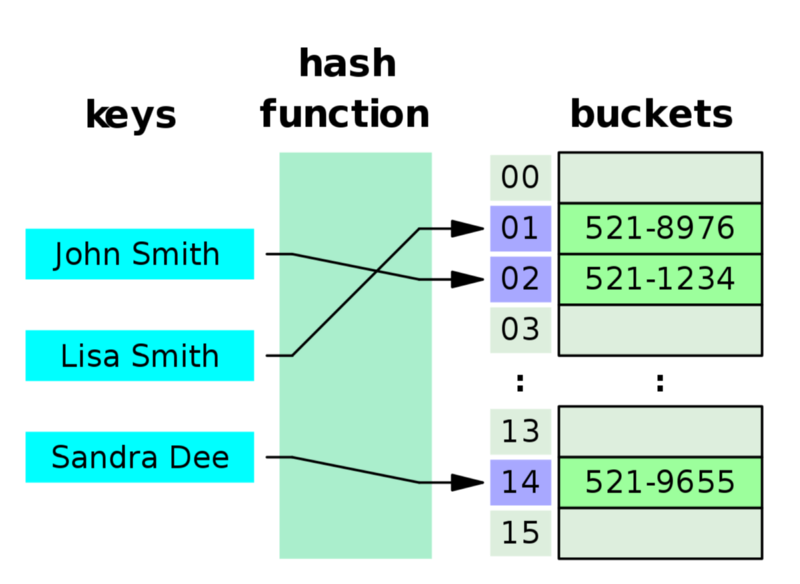
Chúng ta cần tìm ra cách tránh phải lặp qua cả danh sách: đã đến lúc xài hash trong hash table nào.
Bạn có thắc mắc tại sao lại gọi cấu trúc dữ liệu này là hash table không? Đó là bởi một hàm hashing được sử dụng với các khóa mà bạn set và get. Chúng ta sẽ sử dụng hàm này để biến key của chúng ta thành 1 số nguyên i, và lưu value vào chỉ mục i của danh sách. Do vậy khi truy xuất một phần tử, bằng chỉ mục của nó từ một danh sách thì chỉ tốn có O(1) thôi vì vậy ta nói hash table có độ phức tạp O(1).
Hãy làm thử luôn nào:
let hash = require('string-hash')
class DumbMap {
constructor() {
this.list = []
}
get(x) {
return this.list[hash(x)]
}
set(x, y) {
this.list[hash(x)] = y
}
}Ở đây chúng ta dùng một string-hash module, sẽ chuyển đổi một chuỗi thành 1 mã hash dạng số. Chúng ta sẽ lưu trữ và truy xuất phần tử tại chỉ mục index hash(key) của danh sách. Và kết quả benchmark lại:
với nhiều nhiều bản ghi trong map: 0.013msW --- O --- W. Đây chính là điều tôi muốn nói!
Chúng ta sẽ không phải lặp đi lặp lại qua tất cả các phần tử trong danh sách, do đó truy xuất tới một phần tử bất kì trong DumpMap sẽ cực kì nhanh luôn!
Tóm gọn lại luôn nè: hashing làm hash table trở nên vô đối. Không có phép thuật nào luôn. Một ý tưởng vô cùng đơn giản, thông minh và khôn ngoan.
Chọn hàm hashing cũng quan trọng đó.
Đương nhiên, chọn hàm hashing cũng quan trọng lắm. Nếu hàm hash(key) chạy tốn vài giây thì hàm của chúng ta sẽ chậm đi tương đối và tăng cả độ phức tạp.
Và điều quan trọng nữa là hàm hashing không được tạo ra các giá trị trùng nhau - collision, bởi nó sẽ làm hỏng hash table luôn.
Rối trí phải hem? Hãy tìm hiểu kĩ hơn về collision nào.
Collisions
Bạn có thể tưởng rằng "Ui giời, một hàm hashing tốt thì chẳng tạo ra mã lặp collision nào đâu!": thôi nào trở lại mặt đất đê. Google đã có thể tạo ra collision cho thuật toán hashing SHA-1, chỉ là vấn đề thời gian thôi, với sức mạnh siêu máy tính thì một hàm hashing bị crack và cho cùng 1 mã hash cho 2 giá trị đầu vào là có thực. Luôn luôn phải sẵn sàng rằng hàm hashing của bạn có thể tạo ra các collision và phải tạo ra các lớp phòng thủ trước những trường hợp đó.
function divide(int) {
int = Math.round(int / 2)
if (int > 10) {
return divide(int)
}
return int
}
function hash(key) {
let h = require('string-hash')(key)
return divide(h)
}Hàm này dùng mảng 10 phần tử để lưu giá trị, có nghĩa là các phần tử sẽ bị thay thế - một bug to oành khi áp vào DumbMap:
function divide(int) {
int = Math.round(int / 2)
if (int > 10) {
return divide(int)
}
return int
}
function hash(key) {
let h = require('string-hash')(key)
return divide(h)
}Để giải quyết vấn đề này, chúng ta đơn giản là lưu trữ nhiều cặp key-value vào cùng 1 chỉ mục index. Hãy chỉnh sửa lại hash table:
class DumbMap {
constructor() {
this.list = []
}
get(x) {
let i = hash(x)
if (!this.list[i]) {
return undefined
}
let result
this.list[i].forEach(pairs => {
if (pairs[0] === x) {
result = pairs[1]
}
})
return result
}
set(x, y) {
let i = hash(x)
if (!this.list[i]) {
this.list[i] = []
}
this.list[i].push([x, y])Bạn nhận ra đúng không, chúng ta lại trở lại cách triển khai ban đầu: lưu 1 danh sách các cặp key-value và lặp qua mỗi phần tử. Nó sẽ trở nên vô cùng chậm chạp khi có nhiều collision trong cùng 1 chỉ mục trong danh sách.
Thử benchmark với hàm hash() của chúng ta chỉ tạo ra chỉ mục từ 1 đến 10:
với nhiều nhiều bản ghi trong map: 11.919mscòn với hàm hash từ string-hash, tạo ra chỉ mục random:
với nhiều nhiều bản ghi trong map: 0.014msVậy là rõ ràng rồi nhé, việc chọn hàm hash cũng vô cùng quan trọng - phải đủ nhanh để không làm chậm cả quá trình, và cũng phải đủ tốt để không tạo ra nhiều collision.
Thường thì O(1)
Nhớ lời tôi chém gió ban đầu chứ?
Hashtable luôn có độ phức tạp O(1)
Thực ra tôi chém đó: độ phức tạp của một hash table phụ thuộc vào hàm hashing mà bạn chọn. Càng nhiều collision thì độ phức tạp càng tiệm cận O(n).
Một hàm hashing ví dụ:
function hash(key) {
return 0
}sẽ nghĩa là hash table này sẽ có độ phức tạp O(n).
Vì vậy trong độ phức tạp chia làm 3 mức độ: tốt nhất, trung bình và trường hợp tệ nhất. Hashtable có độ phức tạp O(1) là tốt nhất nhưng sẽ tiệm cận dần O(n) ở trường hợp tệ nhất.
Luôn nhớ: Một hàm hashing tốt là chìa khóa để có một hash table hiệu quả --- không hơn cũng không kém.
Tìm hiểu thêm về collision...
Kĩ thuật mà chúng ta sử dụng để sửa DumbMap trong trường hợp có nhiều collision được gọi là separate chaining: chúng ta sẽ lưu toàn bộ các key mà tạo ra collision và một danh sách và lặp qua chúng.
Một kĩ thuật phổ biến khác là open addressing - địa chỉ mở:
- Ở mỗi chỉ mục index của danh sách chúng ta chỉ lưu trữ 1 và chỉ 1 cặp key-value
- Khi cố gắng lưu một cặp ở chỉ mục x, nếu ở đó đã lưu một cặp khác rồi thì sẽ thử lưu cặp mới đó vào x + 1
- Nếu x + 1 đã bị chiếm chỗ thì lại nhảy sang x + 2 và cứ thế...
- Khi truy xuất lại một phần tử, hash key đó và kiểm tra nếu phần tử tại vị trí (x) có trùng key đó không.
- Nếu không thì lại thử truy cập phần tử tại vị trí x + 1
- Cứ lặp lại cho tới cuối danh sách hoặc khi bạn tìm thấy một chỉ mục rỗng - có nghĩa là phần tử đó không có trong hash table
Thông minh, đơn giản, thanh lịch và thường thì vô cùng hiệu quả!
FAQs (hỏi xoay đáp xoáy)
Có phải hash table hash value mà chúng ta sẽ lưu?
Không đúng, chỉ có key được hash để biến thành 1 số nguyên i, và cả key lẫn value sẽ được lưu tại vị trí i trong danh sách.
Những hàm hashing được dùng trong hash table tạo ra các giá trị lặp collision?
Chuẩn đó - vì thế hash table sẽ phải triển khai thêm các biện pháp phòng thủ để tránh gặp bug.
Có phải hash table sử dụng mảng list hay 1 linked list có sẵn?
Nó còn tùy, cả 2 đều có thể sử dụng. Trong ví dụ của chúng ta, mảng trong JavaScript ( [ ] ) có thể thay đổi kích thước động:
> a = []
> a[3] = 1
> a
[ <3 mục trống>, 1 ]Vậy tại sao ta lại chọn JavaScript làm ví dụ? Mảng trong JS là hash table!
Ví dụ:
> a = []
[]
> a["some"] = "thing"
'thing'
> a
[ some: 'thing' ]
> typeof a
'object'Đùa chứ, chắc chỉ có mỗi JavaScript là vậy.
JavaScript có lẽ là ngôn ngữ dễ hiểu nhất khi làm code mẫu. JS có lẽ không phải là ngôn ngữ tuyệt nhất nhưng những ví dụ này mong rằng đủ rõ ràng.
Đây có phải là một cách triển khai hash table tốt? Nó có đơn giản như vậy?
Không, không hẳn là vậy.
Hãy tham khảo thêm bài viết này "triển khai hash table trong JavaScript". Sẽ có nhiều trường hợp hơn, và còn nhiều tài liệu tham khảo khác tại:
Kết bài:
Hash table là một ý tưởng vô cùng thông minh được sử dụng rộng rãi: bất cứ đâu khi mà bạn tạo từ điển với Python, một mảng liên kết trong PHP hoặc Map trong JavaScript. Chúng đều dựa vào cùng một ý tưởng tuyệt vời giúp chúng ta lưu trữ và truy xuất phần tử chỉ bằng key, và gần như chỉ tốn O(1).
Bình luận