Giới thiệu
Web scraping là quá trình tự động trích xuất lượng lớn dữ liệu từ các trang web. Nó cho phép thu thập nhanh chóng thông tin để nghiên cứu, giám sát, phân tích dữ liệu, v.v.
Bài viết này trình bày những kiến thức cơ bản về cách sử dụng Scrapy, một framework trích xuất dữ liệu web phổ biến của Python, để xây dựng một công cụ mạnh mẽ nhằm thu thập dữ liệu.
Tại sao Web Scraping lại hữu ích
Một vài ứng dụng thực tế bao gồm:
- Giám sát giá - Theo dõi giá trên các cửa hàng thương mại điện tử để biết thông tin thị trường.
- Tạo khách hàng tiềm năng - Thu thập dữ liệu danh sách doanh nghiệp, bao gồm thông tin liên hệ của nhóm bán hàng và tiếp thị.
- Giám sát nội dung - Kiểm tra các trang web liên tục để biết những thay đổi nội dung có liên quan như thông báo của công ty hoặc tin tức về đối thủ cạnh tranh. Rất phù hợp cho các nhóm PR và quản lý danh tiếng, những người phải cập nhật tin tức trong ngành.
- Xây dựng bộ dữ liệu học máy - Các trang web có thể cung cấp khối lượng văn bản và dữ liệu thích hợp, chất lượng cao. Với một số thao tác làm sạch, dữ liệu web là tài liệu đào tạo tuyệt vời cho các mô hình NLP và ML.
Tại sao lại là Scrapy
Có rất nhiều framework Python dành cho Web Scraping như BeautifulSoup, Crawlee,… nhưng Scrapy có một số ưu điểm:
- Đã được thử nghiệm trong hơn một thập kỷ phát triển và triển khai các sản phẩm lớn
- Tích hợp tốt với các Web và Python data science framework
- Nhanh chóng và được xây dựng để mở rộng quy mô thông qua kiến trúc không đồng bộ của nó
- Một hệ sinh thái rộng lớn bao gồm các plugin có sẵn
- Scrapy có thể tăng tốc độ thu thập dữ liệu một cách đáng kể trong khi yêu cầu tài nguyên cơ sở hạ tầng ở mức tối thiểu.
Hướng dẫn sử dụng Scrapy để thu thập thông tin
Ở phần này, chúng ta cùng thực hiện một ví dụ đơn giản sử dụng Scrapy để thu thập thông tin về sản phẩm giày nam Nike từ trang chủ: https://www.nike.com/vn/w/mens-shoes-nik1zy7ok
Cài đặt môi trường
Tạo môi trường ảo python
Nếu bạn đã quen với python, việc sử dụng môi trưởng ảo hẳn không còn quá xa lạ. Nếu chưa từng làm việc với môi trường ảo python, bạn có thể tìm hiểu thêm tại đây
Tạo môi trường
web-scraping:python3 -m venv web-scraping source web-scraping/bin/activateCài đặt Scrapy
Sử dụng
pipđể cài framework scrapypip install scrapyTạo project folder
mkdir shoes-scraper cd shoes-scraper
Bắt đầu làm việc với Scrapy
Tạo một Spider
Khi sử dụng Scrapy, một tiến trình thu thập dữ liệu được gọi là một
Spider, ở phần này chúng ta tạo raShoeSpidernhư sau:# filename: shoes_spider.py import scrapy class ShoeSpider(scrapy.Spider): name = 'shoes-spider' start_urls = ['https://www.nike.com/vn/w/mens-shoes-nik1zy7ok']Tất cả Spider kế thừa từ class gốc
scrapy.Spider. Class này sẽ có 2 thuộc tính bắt buộc:name: tên của spiderstart_urls: danh sách các URL mà bạn bắt đầu thu thập thông tin từ đó. Chúng ta sẽ bắt đầu với một URL.
Chúng ta sẽ test thử Spider mới tạo. Thông thường, các file Python được chạy bằng lệnh như
python path/to/file.py. Tuy nhiên, Scrapy có hỗ trợ bộ CLI riêng.Khởi động scraper bằng lệnh sau:
scrapy runspider shoes_spider.pyTrích xuất dữ liệu
Chúng ta đã tạo một chương trình rất cơ bản để kéo một trang xuống nhưng nó chưa thực hiện bất kỳ thao tác tìm kiếm hoặc thu thập dữ liệu nào. Khi viết một Spider, điều tiên quyết là bạn phải hiểu cấu trúc HTML của trang web đó, từ đó có thể trích xuất ra thông tin bạn cần.
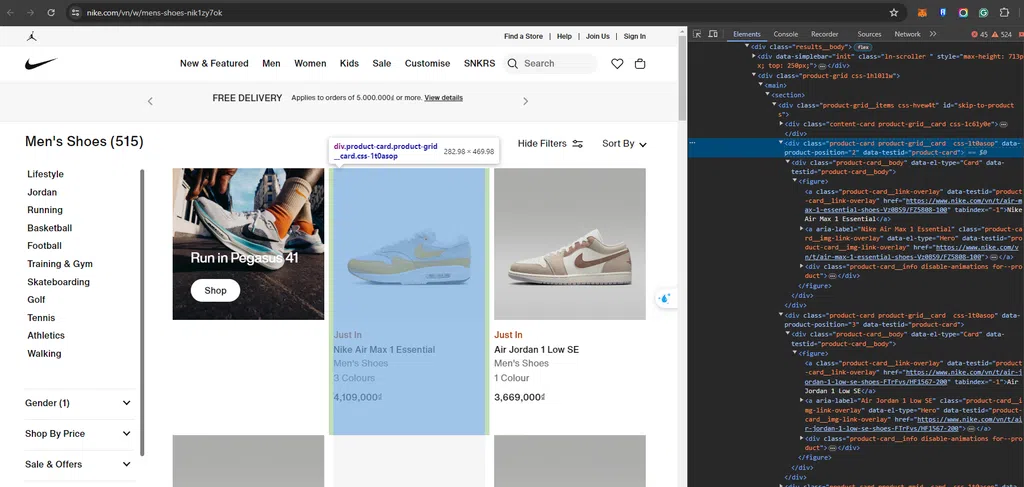
Ví dụ bạn đang muốn lấy thông tin về sản phẩm từ trang web https://www.nike.com/vn/w/mens-shoes-nik1zy7ok. Chúng ta cùng thực hiện inspect trang web để lấy thông tin HTML như sau:
Chúng ta có thể thấy mỗi Card sản phẩm là một thẻ HTML classproduct-card product-grid__cardvới cấu trúc như sau:<div class="product-card product-grid__card css-1t0asop" data-product-position="2" data-testid="product-card"> <div class="product-card__body" data-el-type="Card" data-testid="product-card__body"> <figure> <a class="product-card__link-overlay" data-testid="product-card__link-overlay" href="https://www.nike.com/vn/t/air-max-1-essential-shoes-Vz0BS9/FZ5808-100" tabindex="-1">Nike Air Max 1 Essential</a> <a aria-label="Nike Air Max 1 Essential" class="product-card__img-link-overlay" data-el-type="Hero" data-testid="product-card__img-link-overlay" href="https://www.nike.com/vn/t/air-max-1-essential-shoes-Vz0BS9/FZ5808-100"> <div class="wall-image-loader css-1la3v4n" data-testid="wall-image-loader"> <img alt="Nike Air Max 1 Essential Men's Shoes" class="product-card__hero-image css-1fxh5tw" height="100%" loading="eager" sizes="" src="https://static.nike.com/a/images/c_limit,w_592,f_auto/t_product_v1/c25569a6-545c-439c-bf6e-1b214a51fd9e/air-max-1-essential-shoes-Vz0BS9.png" width="100%" /> <noscript><img alt="Nike Air Max 1 Essential Men's Shoes" class="product-card__hero-image css-1fxh5tw" height="400" loading="lazy" width="400" /></noscript> </div> </a> <div class="product-card__info disable-animations for--product"> <div class="product_msg_info"> <div data-testid="product-card__messaging" class="product-card__messaging accent--color">Just In</div> <div class="product-card__titles"> <div class="product-card__title" id="Nike Air Max 1 Essential" role="link">Nike Air Max 1 Essential</div> <div class="product-card__subtitle" role="link">Men's Shoes</div> </div> </div> <div class="product-card__count-wrapper show--all false" data-testid="product-card__count-wrapper "> <div class="product-card__count-item"> <button aria-disabled="false" aria-expanded="false" class="product-card__colorway-btn" data-testid="product-card__colorway-btn" type="button"> <div aria-label="Available in 3 Colors" class="product-card__product-count">3 Colours</div> </button> </div> </div> <div class="product-card__animation_wrapper"> <div class="product-card__price-wrapper"> <div class="product-card__price" data-testid="product-card__price" role="link"> <div class="product-price__wrapper css-9xqpgk"><div class="product-price vn__styling is--current-price css-11s12ax" data-testid="product-price">4,109,000₫</div></div> </div> </div> </div> </div> </figure> </div> </div>Từ đây để lấy các thông tin cần thiết chúng ta cần quan tâm đến các class như sau:
- Tên sản phẩm: thẻ
div, classproduct-card__title - Số lượng màu: thẻ
div, classproduct-card__product-count - Giá sản phẩm: thẻ
div, classproduct-price
Từ đây, chúng ta cùng hoàn thành chương trình Spider như sau:
# shoes_spider.py import scrapy class ShoeSpider(scrapy.Spider): name = "shoes_spider" start_urls = ['https://www.nike.com/vn/w/mens-shoes-nik1zy7ok'] def parse(self, response): for product in response.css('div.product-card'): name = product.css('div.product-card__title::text').get() count = product.css('div.product-card__product-count::text').get() price = product.css('div.product-price::text').get() yield { 'name': name, 'count': count, 'price': price } custom_settings = { 'FEEDS': { 'shoes.csv': { 'format': 'csv', 'fields': ['name', 'count', 'price'] } } }Ở phần
custom_settingschúng ta cấu hình để ghi kết quả ra file csvSau khi thực hiện lệnh:
scrapy runspider shoes_spider.pyChúng ta thu được file csv
shoes.csvnhư sauname,count,price Nike Air Max 1 Essential,3 Colours,"4,109,000₫" Air Jordan 1 Low SE,1 Colour,"3,669,000₫" Jordan Stadium 90,5 Colours,"4,109,000₫" Nike Zoom Vomero 5,1 Colour,"4,699,000₫" Air Jordan 1 Low,1 Colour,"3,519,000₫" Nike Air Force 1 '07,4 Colours,"3,239,000₫" Nike Dunk Low Retro,5 Colours,"2,929,000₫" Nike Air Max Dn,1 Colour,"4,999,000₫" Nike Air Max Dn SE,1 Colour,"4,999,000₫" Air Jordan 1 Low,3 Colours,"3,239,000₫" Jordan Max Aura 6,2 Colours,"3,829,000₫" Nike Pegasus 41,5 Colours,"3,829,000₫" Nike V2K Run,4 Colours,"3,519,000₫" Nike P-6000 Premium,1 Colour,"3,519,000₫" Nike G.T. Cut 3 EP Blueprint,1 Colour,"5,589,000₫" Nike InfinityRN 4 Blueprint,1 Colour,"4,699,000₫" Nike Pegasus EasyOn Blueprint,1 Colour,"3,829,000₫" Nike Pegasus 41,1 Colour,"4,109,000₫" Nike Air Max 90,3 Colours,"3,519,000₫" Air Jordan 1 Low G,5 Colours,"4,109,000₫" Air Jordan 1 Low Quai 54,1 Colour,"4,109,000₫" Nike Invincible 3,2 Colours,"5,279,000₫" Nike Juniper Trail 2 GORE-TEX,1 Colour,"3,369,000₫" Nike Streakfly,3 Colours,"4,699,000₫"Kết luận
Bài viết này đã hướng dẫn bạn một ví dụ cơ bản sử dụng Scrapy framework để thu thập dữ liệu từ trang web. Hi vọng các bạn có thể sử dụng kiến thức cho các bài toán thực tế mà bạn cần giải quyết.
- Tên sản phẩm: thẻ
Bình luận