PostgreSQL lưu trữ dữ liệu như thế nào ?
1. Database cluster, database, table
Khi bạn cài đặt thành công PostgreSQL (cài trực tiếp hoặc cài bằng Docker) trên một con server (local hoặc remote), khi đó bạn đã tạo ra một database cluster
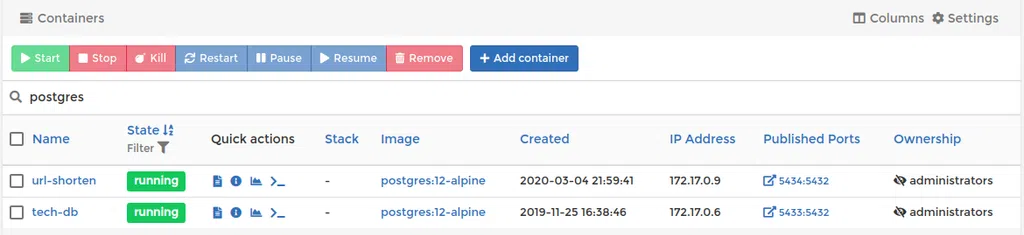
Như trong ảnh trên, mình dùng Docker để chạy 2 database cluster trên cùng 1 máy host, mỗi cluster chạy ở một cổng khác nhau
Bên trong mỗi database cluster sẽ bao gồm nhiều database khác nhau:
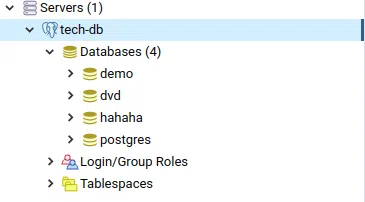
Bên trong mỗi database (datatabase nhé, không phải là database cluster :v) sẽ bao gồm: table ( bảng ), index, view, ...
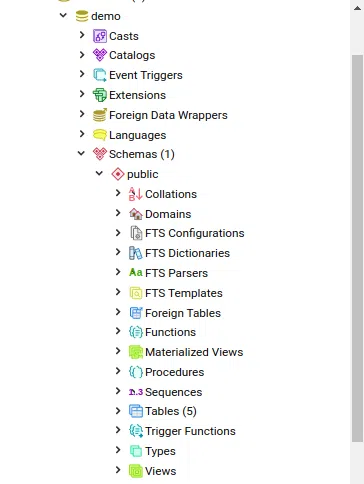
Mỗi một database, bảng, view, function, ... sẽ được đại diện bởi một chuỗi OID (Object ID, giống như là primary key trong bảng ấy :D), và thông tin về các chuỗi ID này sẽ được lưu trong các bảng system catalogs của Postgres. Ví dụ, để lấy OID của database demo, ta chạy lệnh sau:
SELECT datname, oid FROM pg_database WHERE datname = 'demo';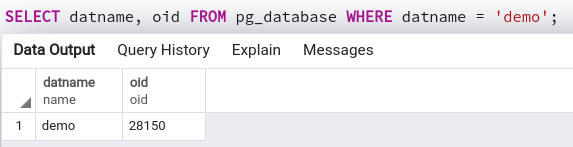
Để lấy OID của một bảng, ví dụ bảng customer trong database demo, ta dùng lệnh sau:
SELECT relname, oid FROM pg_class WHERE relname = 'customer';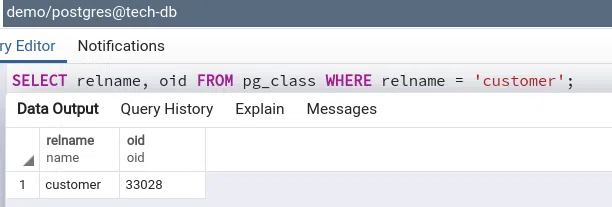
OID này có vai trò rất quan trọng trong phần sau, khi chúng ta tìm hiểu về cấu trúc file và thư mục trong Postgres
2. Hệ thống file và thư mục trong Postgres
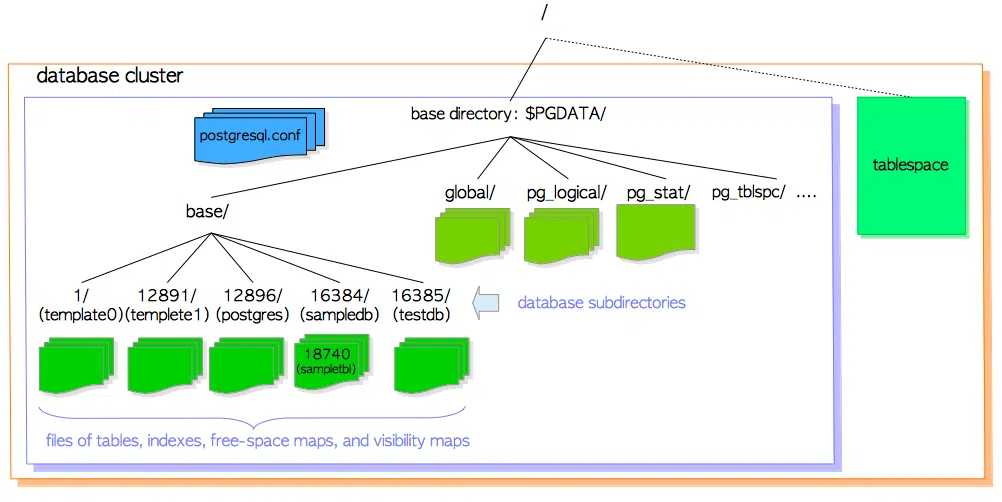
Khi một database cluster được khởi tạo, tương ứng với nó là một thư mục được tạo ra. Thư mục này các bạn có thể coi nó là thư mục gốc (aka trùm cuối :v) trong Postgres, và thông thường đường dẫn của thư mục này sẽ được gán cho biến môi trường $PGDATA

Bên trong thư mục gốc này là rất nhiều các file và thư mục con, ví dụ như file pg_hba.conf để quản lý authentication, postgresql.conf để thiết lập các cấu hình, thư mục pg_wal để quản lý các WAL (Write Ahead Log), ... trong đó có một thư mục mà chúng ta cần lưu ý, đó là thư mục base:

Bên trong thư mục base này là các thư mục con, mỗi thư mục con tương ứng với một database trong database cluster. Chúng ta sẽ dựa vào OID của database để xác định xem nó tương ứng với thư mục nào. Ví dụ, ở phần 1 chúng ta đã xác định được OID của database demo là 28150, vậy thì dữ liệu của database này sẽ được để ở thư mục $PGDATA/base/28150
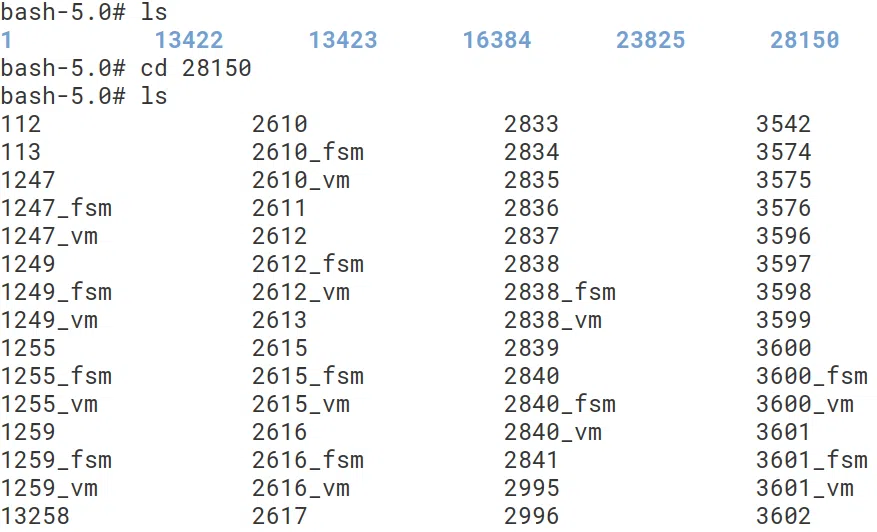
Bên trong thư mục 28150 này gồm các file lưu dữ liệu của các object như table, index, views, ... Tất nhiên, chúng ta sẽ lại dựa vào OID để xác định xem mỗi object sẽ tương ứng với file nào. Ví dụ, ở phần 1 chúng ta đã lấy được OID của bảng customer là 33028:

Tổng kết lại, chúng ta có thể hình dung cấu trúc file và thư mục trong 1 database cluster như sau:
Ở phần sau, chúng ta sẽ tìm hiểu xem bên trong 1 file lưu dữ liệu của bảng thì sẽ bao gồm những thành phần gì
3. Các thành phần bên trong 1 table file
Mỗi file lưu dữ liệu của table sẽ được chia ra thành nhiều page: mỗi page nặng 8KB và được đánh số thứ tự từ 0, số thứ tự này được gọi là page block
Bên trong mỗi page sẽ lưu 3 loại dữ liệu :
- Tuple: Đây chính là dữ liệu của từng bản ghi (row) trong bảng. Các tuple sẽ xếp chồng lên nhau theo cấu trúc stack
- Line pointer: Mỗi pointer nặng 4 byte và trỏ đến từng tuple. Các pointer sẽ xếp cạnh nhau theo cấu trúc array. Mỗi khi có một tuple mới được lưu vào page, một line pointer mới tương ứng cũng sẽ được thêm (push) vào array
- Header: Nặng 24 byte, lưu các thông tin dạng metadata về page
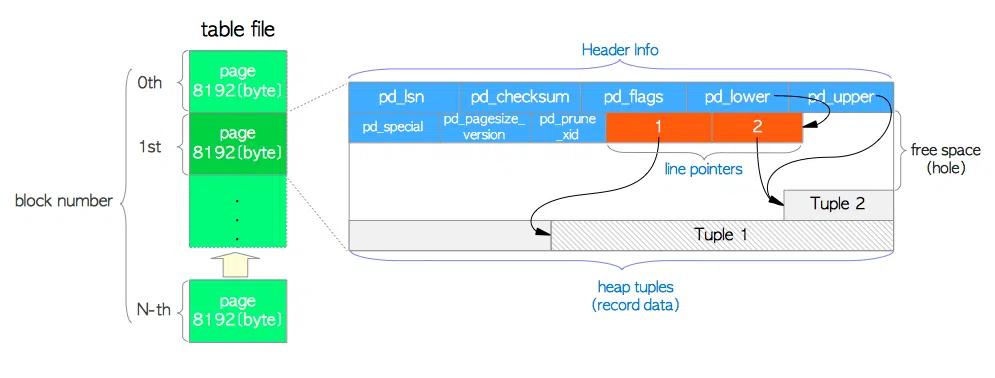
Trong 1 bảng gồm rất nhiều bản ghi, để xác định xem bản ghi đó được lưu ở vị trí nào trong file, Postgres sẽ sử dụng 2 thông tin:
- Page block: bản ghi đó nằm ở page số mấy trong file
- Vị trí của line pointer trong mảng các line pointers
2 thông tin này được gộp lại để tạo nên một TupleID. TupleID sẽ được sử dụng để đọc dữ liệu từ bảng bằng phương pháp Index Scan
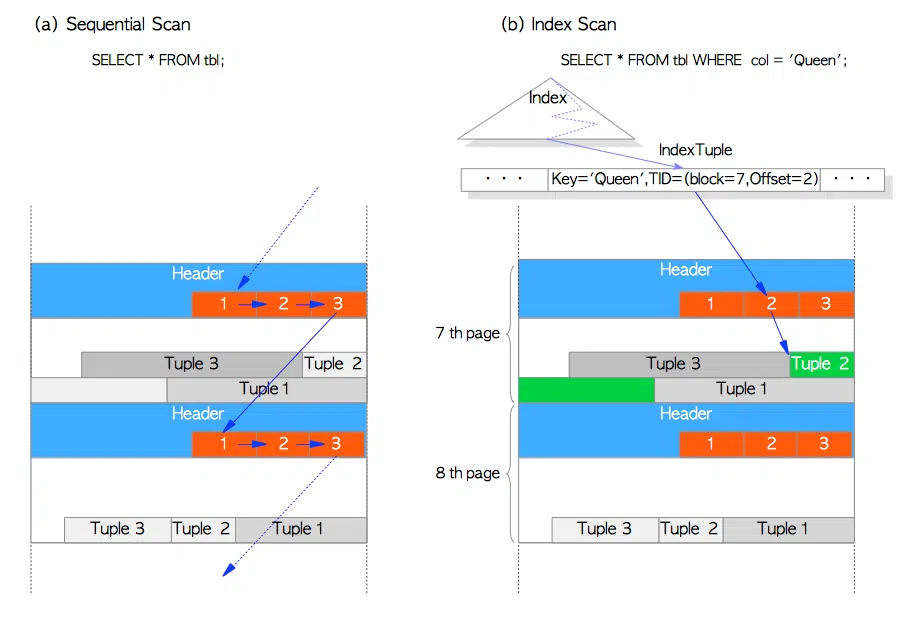
4. Đọc dữ liệu từ bảng bằng Sequential Scan and Index Scan
Để đọc dữ liệu từ bảng, có 2 phương pháp phổ biến :
- Sequential Scan: Lần lượt đọc từng page, trong mỗi page lại lần lượt đọc từng line pointer để lấy ra các tuple tương ứng
- Index Scan: Thay vì lần lượt đọc từng page và dò từng line pointer, Index Scan sẽ sử dụng TupleID để chọc thẳng vào page và lấy ra tuple cần tìm
Nguồn tham kharo: Database Cluster, Databases, and Tables
Bình luận