Trigram là gì
Trigram là một tập hợp gồm 3 ký tự liên tiếp được lấy ra từ một chuỗi. Chúng ta có thể đo mức độ giống nhau của 2 chuỗi bằng cách đếm số lượng trigram mà chúng dùng chung. Ý tưởng đơn giản này rất có hiệu quả để đo mức độ giống nhau của các từ trong nhiều ngôn ngữ tự nhiên
Muốn sử dụng Trigram trong Postgres, trước hết chúng ta cần cài extension pg_trgm
Ở đây mình dùng ứng dụng DBeaver để kết nối với CSDL Postgres để thực hiện truy vấn đến database
CREATE EXTENSION pg_trgm;
Sau đó chúng ta có thể kiểm tra lại xem extension đã được cài đặt hay chưa
SELECT * FROM pg_extension;

Note:
pg_trgm sẽ bỏ qua các ký tự không phải chữ và số khi chúng ta trích xuất trigram từ một chuỗi, ví dụ với chuỗi "hel-lo+" thì các ký tự "-, +" sẽ được bỏ qua. Ví dụ, bộ trigram trong chuỗi “cat” là “c”, “ca”, “cat” và “at”. Bộ trigram trong chuỗi “foo | bar” là “f”, “fo”, “foo”, “oo”, “b”, “ba”, “bar” và “ar”.
Một số function sử dụng trong Trigram
1.show_trgm ( text ) → text[]
Trả về danh sách trigram của một chuỗi
SELECT show_trgm('hello')
Kết quả : { h, he,ell,hel,llo,lo }
2.set_limit ( real ) → real
Khi chúng ta so sánh 2 chuỗi chúng ta cần đặt ra 1 ngưỡng để để xem 2 chuỗi này có giống nhau hay không? Nếu vượt qua ngưỡng này thì có thể coi 2 chuỗi đó gần giống nhau. Ngưỡng này có giá trị trong khoảng 0 -> 1. Càng về 1 thì 2 chuỗi đó càng giống nhau (mặc định định là 0.3)
(Nếu không được chấp nhận sử dụng SET pg_trgm.similarity_threshold để thay thế)
select set_limit(0.4)
3.show_limit () → real
Trả về giá trị của ngưỡng hiện tại (Nếu không được chấp nhận sử dụng SHOW pg_trgm.similarity_threshold để thay thế)
select show_limit()
// Kết quả : 0.4 do chúng ta đã set_limit ở trên
4.similarity ( text, text ) → real
Trả về một giá tị cho biết mức độ giống nhau của hai chuỗi. Phạm vi của kết quả là 0 (nếu hai chuỗi hoàn toàn khác nhau) đến 1 (nếu hai chuỗi giống hệt nhau).
select similarity('word', 'two words')
-- Kết quả : 0.363636
-- Giải thích
SELECT show_trgm('word') -- w, wo, wor, ord, or (5)
SELECT show_trgm('two words') -- t,tw, two, wo, w, wo, wor, ord, rds, ds (10)
-- Trigram tương đồng : 4
-- Trigram không tương đồng : 11
-- Tỉ lệ : 4/11 = 0.363636
5.word_similarity ( text, text ) → real
Trả về một giá trị cho biết sự giống nhau lớn nhất giữa danh sách trigram trong chuỗi đầu tiên và danh sách trigram có thứ tự trong chuỗi thứ hai.
SELECT word_similarity('word', 'two words');
-- Kết quả : 0.8
-- Giải thích
SELECT show_trgm('word') -- w, wo, wor, ord, or (5)
SELECT show_trgm('two words') -- t,tw, two, wo, w, wo, wor, ord, rds, ds (10)
-- Tìm thấy : w, wo, wor, ord (4) -> 4/5 = 0.8
Trong chuỗi thứ nhất chúng ta có tập trigram là {" w"," wo","wor","ord","rd "}. Tương tự trong chuỗi thứ 2, tập trigram đã được sắp xếp là {" t"," tw","two","wo "," w"," wo","wor","ord","rds","ds "}. Ở đây chúng ta thấy có tập trigram {" w"," wo","wor","ord"} có giá trị tương ứng trong tập trigram của chuỗi thứ 2, mức độ giống nhau ở đây là 0.8
6.strict_word_similarity ( text, text ) → real
SELECT strict_word_similarity('word', 'two words')
-- Kết quả : 0.5714286
-- Giải thích
SELECT show_trgm('word') -- w, wo, wor, ord, or (5)
SELECT show_trgm('two words') -- t,tw, two, wo, w, wo, wor, ord, rds, ds (10)
-- Trigram tương đồng : 4 (w, wo, wor, ord)
-- Trigram không tương đồng : 7 (w, wo, wor, ord, rds, ds, or)
-- Tỉ lệ : 4/7 = 0.5714286
Tương tự như word_similarity
Function strict_word_similarity hữu ích để tìm kiếm sự tượng tự trong toàn bộ các từ, trong khi word_similarity lại phù hợp khi thực hiện tìm kiếm cho từng phần của từ
Operator
Ở đây chúng ta tìm hiểu qua một số Operator thường hay được sử dụng
| Operator | Mô tả |
|---|---|
| text % text → boolean | Trả về true nếu các đối số của nó có độ tương tự lớn hơn giá trị ngưỡng hiện tại do pg_trgm.similarity_threshold đặt ra |
| text <% text → boolean | Trả về true nếu độ tương tự của tập trigram của đối số thứ nhất và tập các trigram được sắp xếp của đối số thứ 2 lớn hơn giá trị ngưỡng hiện tại do pg_trgm.similarity_threshold đặt ra |
| text %> text → boolean | Ngược lại với toán tử <% |
| ... | ... |
Các bạn có thể tham khảo thêm thông tin ở đây : https://www.postgresql.org/docs/14/pgtrgm.html
Example
Đầu tiên chúng ta sẽ tạo bảng Tag
CREATE TABLE share.tag(
id text PRIMARY KEY,
name text NOT NULL,
slug text NOT NULL
);
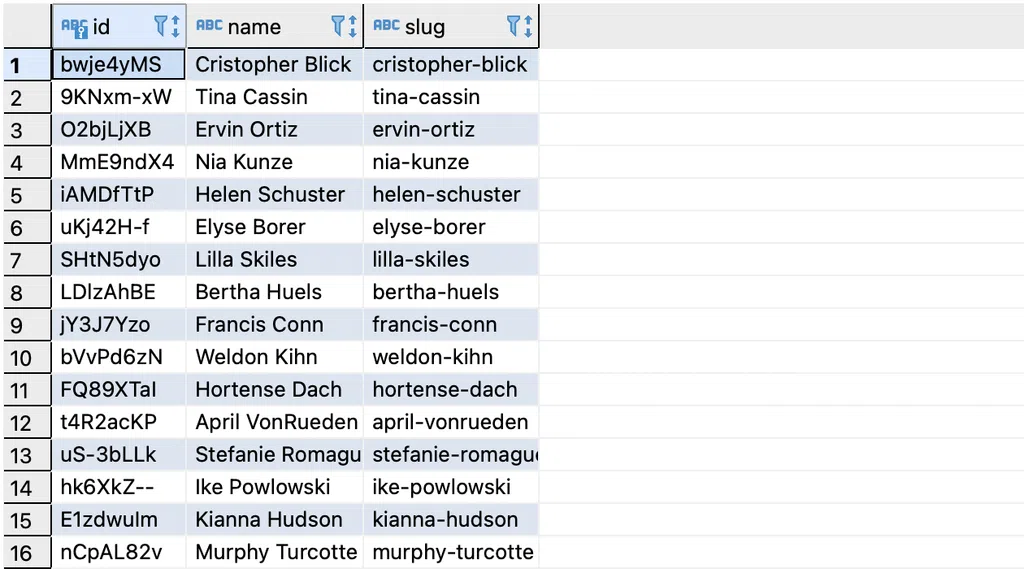
Tiếp theo chúng ta tạo một số dữ liệu giả cho bảng vừa tạo
Ví dụ
pg_trgm module cung cấp cho chúng ta GIST và GIN index cho phép tạo index trên các cột giúp tìm kiếm nhanh hơn
Ví dụ tạo GIST index:
CREATE INDEX trgm_idx ON share.tag USING GIST (name gist_trgm_ops)
hoặc GIN index:
CREATE INDEX trgm_idx ON share.tag USING GIN (name gin_trgm_ops)
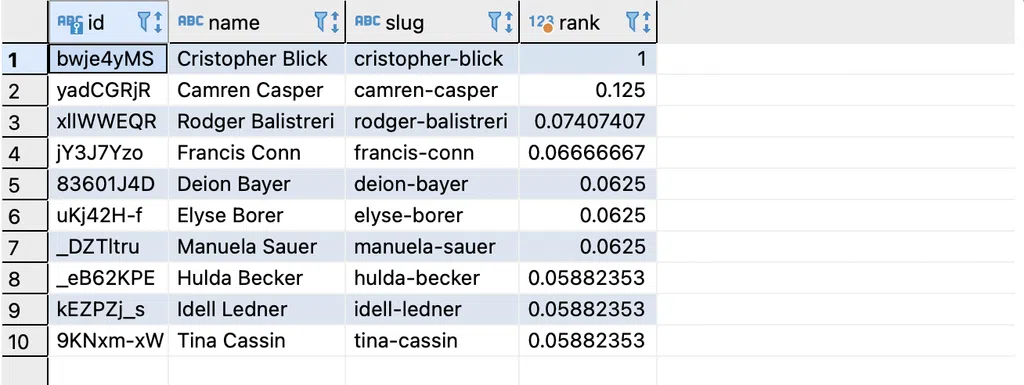
Bây giờ chúng ta sẽ sử dụng index của cột name để tìm kiếm 1 chuỗi với trigram để xem mức độ tương tự như thế nào
SELECT t2."id", t2."name", t2.slug, strict_word_similarity('Cristopher', t2."name") AS rank
FROM "share".tag t2
ORDER BY rank DESC, t2."name"
limit 10
Kết quả
Bình luận