Apple sử dụng nhận diện khuôn mặt để mở khóa thiết bị di động; Facebook sử dụng hệ thống gán tag mặt bạn bè để kết nối cộng đồng; các công ty tài chính nhăm nhe sử dụng nhận diện mặt để xác thực thanh toán thay cho thẻ cứng; sân bay, nhà ga sử dụng nhận diện mặt để kiểm soát an ninh; trường học, công ty muốn sử dụng các hệ thống điểm danh, chấm cộng tự động thông qua xác thực khuôn mặt,…
Đó là những ví dụ điển hình cho sự phát triển mạnh mẽ và phổ biến của bài toán face recognition hay nhận diện mặt người trong thực tế.
Đã có nhiều nghiên cứu về bài toán này, nhiều mô hình được đưa ra, nhiều pre-trained model được public cùng với các bộ dữ liệu mặt người công khai miễn phí. Các kết quả đạt được trên bộ dữ liệu này là rất tốt thế nhưng nhiều quan sát cho thấy việc áp dụng chúng lên các bài toán thực tế của Việt Nam lại chưa được tốt như vậy. Với mục đích xây dựng một dataset dành riêng cho mục đích nghiên cứu, tối ưu hóa bài toán nhận diện mặt người cho người Việt, mình xin được giới thiệu một mini-dataset VN-celebrity với hơn 23k khuôn mặt của hơn 1000 người Việt. Hy vọng bộ dữ liệu này sẽ phục vụ được nhu cầu nghiên cứu của các bạn và nhiều hơn nữa các pre-trained model dành riêng cho người Việt được public và kể thừa.
Qua bài viết này, mình sẽ giới thiệu về cách mà mình thu thập, tổng hợp dữ liệu. Qua đó bạn có thể xây dựng 1 bộ dữ liệu cho riêng mình hoặc đóng góp thêm vào vào bộ dữ liệu này giúp nó ngày càng mở rộng. (Hiện tại, bộ dữ liệu đã được public hoàn toàn cho mục đích học tập và nghiên cứu tại đây.)
Xây dựng danh sách tên người nổi tiếng
Trước khi tiến hành thu thập bộ dữ liệu khuôn mặt người Việt cho quá trình nghiên cứu, điều mình băn khoăn nhất là vấn đề quyền riêng tư và bản quyển hình ảnh. Nguồn dữ liệu mặt người lớn nhất có thể tiếp cận và thu thập mình nghĩ là mạng xã hội, tuy nhiên, đây cũng là điểm cấm do vấn đề về quyền riêng tư. Việc sử dụng các đoạn script vào trang cá nhân của người khác kéo ảnh và thông tin của họ về sử dụng là không được phép (mặc dù mình biết có những công ty đang sử dụng nguồn dữ liệu này là chủ yếu). Theo như tìm hiểu một thời gian, mình được biết nếu chỉ thu thập nhằm mục đích nghiên cứu, mình có thể tiếp cận những nguồn dữ liệu mở hơn đó chính là Google Image (mặc dù số ảnh xác định được danh tính của nó ít hơn rất nhiều so với mạng xã hội). Dĩ nhiên, nếu người xuất hiện trong ảnh yêu cầu mình không được sử dụng hình ảnh của họ nữa, đấy là quyền của họ).
Để có thể lấy được ảnh đã được xác định danh tính từ Google Image (chủ yếu ảnh từ các báo), mình cần một danh sách các tên để tiến hành Search. Những cái tên này phải đủ nổi để mình có thể tìm kiếm tên của họ một cách dễ dàng. Mình đã sử dụng Wikipedia Việt Nam để định nghĩa danh sách này vì những cái tên được viết trên đây đủ nổi để mình có thể dễ dàng tìm ra họ.
Nằm trong cùng một nền tảng với Wikipedia là kho lưu trữ Wikidata, một cơ sở dữ liệu thứ cấp tự do, đa ngôn ngữ, chuyên thu thập dữ liệu có cấu trúc nhằm hỗ trợ cho các dự án khác thuộc nền tảng Wikimedia. Thực sự trong thời gian gần đây, mình sử dụng dữ liệu từ nền tảng Wiki khá nhiều.
Để lấy được dữ liệu tên người Việt trên Wikipedia một cách đơn giản nhất, bạn chỉ cần vào Wikidata Query, thực hiện 1 truy vấn như sau:
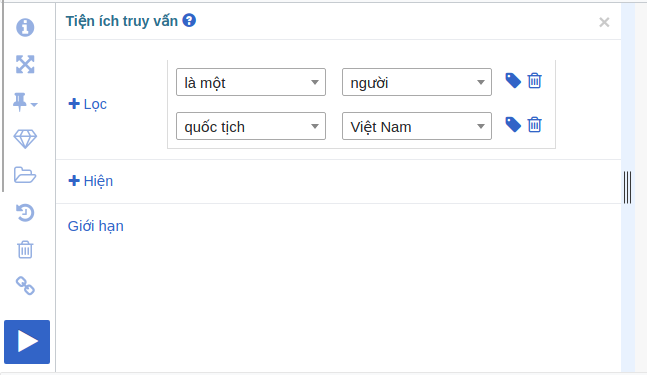
Sau đó tải kết quả trả về dưới dàng Json hoặc CSV.
Tuy nhiên, mình có tìm hiểu về SPARQL và mình thích code một chút hơn.
Đầu tiên cài đặt thư viện cần thiết.
pip install sparqlwrapperTiếp theo, mình thực hiện 1 truy vấn(bạn cũng có thể sinh đoạn code này trên giao diện của Wikidata Query bằng việc click vào phần mã nguồn bên trên bảng kết quả).
from SPARQLWrapper import SPARQLWrapper, JSON
endpoint_url = "https://query.wikidata.org/sparql"
query = """SELECT ?person ?personLabel WHERE {
SERVICE wikibase:label { bd:serviceParam wikibase:language "vi, en". }
?person wdt:P31 wd:Q5.
?person wdt:P27 wd:Q881.
}"""
def get_results(endpoint_url, query):
sparql = SPARQLWrapper(endpoint_url)
sparql.setQuery(query)
sparql.setReturnFormat(JSON)
return sparql.query().convert()
results = get_results(endpoint_url, query)
list_name_celeb = []
for result in results["results"]["bindings"]:
list_name_celeb.append(result["personLabel"]["value"])
Kết quả mình thu được cũng là một danh sách tên người có trên Wikipedia.
Phân tích code một chút.
SERVICE wikibase:label { bd:serviceParam wikibase:language "vi, en". }Mình lấy những cái tên từ Wikipedia tiếng Việt và tiếng Anh thay vì tất cả.
?person wdt:P31 wd:Q5.
?person wdt:P27 wd:Q881.Trong WIkidata, có thể hiểu các giá trị bắt đầu P là chỉ thuộc tính, Q là giá trị của các thuộc tính đó. P31 là một phân loại mà đối tượng này là một thành viên hoặc một ví dụ cụ thể, là một thực thể của nhã lớp nào đó (đối tượng thường có nhãn tên thích hợp) và Q5 chính là nhãn lớp của nó, nhãn lớp human. Tương tự, thuộc tính P27 ở đây là chỉ đến quốc tịch, Q881 là Việt Nam.
Trong truy vấn này, mình lấy ra tên của những người có quốc tịch là Việt Nam ở trên WIki tiếng Anh và tiếng Việt.
Để có thể khai thác nhiều thông tin hơn từ Wikipedia, chắc chắn bạn nên tìm hiểu 1 chút về SPARQL.
Thu thập dữ liệu ảnh sử dụng Google Image Search
Sau khi có được danh sách người có tên trên Wikipedia, mình bắt đầu tiến hành tìm kiếm ảnh của họ trên Google Image Search. Thật may là phần này chúng ta không phải code toàn bộ script crawl vì đã có 1 open source là Google Images Download. Việc sử dụng open source này khá đơn giản, bạn chỉ cần cài đặt theo hướng dẫn tại trang chủ của package và chạy đoạn script sau:
from google_images_download import google_images_download
response = google_images_download.googleimagesdownload()
for x in tqdm(list_name_celeb):
arguments = {"keywords":x, "limit":50}
absolute_image_paths = response.download(arguments)Sau khi chạy đoạn code trên, chúng ta sẽ thu được 1 thư mục có tên download chứa tất cả các thư mục con ứng với ảnh và tên của mỗi người có trong list_name_celeb.
Lưu ý rằng, đây mới chỉ là những bức ảnh trả về dưới sự hỗ trợ của Google Images Download với từ khóa kèm theo, chưa thể khẳng định được kết quả trả về là của người đó hoặc bức ảnh chỉ có người đó. Ta cần có một bước kiểm tra lại. Ví dụ như hình ảnh thu được của ca sĩ Tóc Tiên như hình dưới đây:
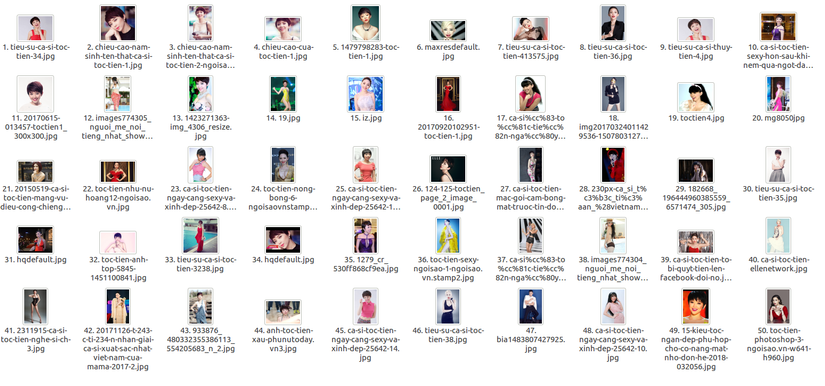
Ở đây mỗi người mình chỉ lấy ra 50 ảnh, bạn có thể lấy nhiều hơn bằng cách thay đổi giá trị của trường limit.
Face detection: Phát hiện và trích xuất mặt trong ảnh
Đến giờ, chúng ta đã có được rất nhiều ảnh của những nhân vật được có tên trong list_name_celeb. Tuy nhiên, như đã đề cập ở trên, dữ liệu này có nhiễu, rất nhiều nhiễu. Ảnh trả về có thể là của một người khác hoặc có nhiều hơn một người trong ảnh.
Mục đích của chúng ta cũng là xây dựng một bộ dataset về mặt người để nghiên cứu các bài toán như Face recognition, Face verification,… nên chúng ta chỉ quan tâm đến phần mặt người có trong các bức ảnh.
Để trích xuất ra phần khuôn mặt trong các bức ảnh, các pre-trained model cho bài toán face detection được xem xét và mình đã quyết định sử dụng FaceNet’s MTCNN của David Sandberg.
Phần khuôn mặt trong ảnh được trích xuất ra và theo đổi kích thước về kích thước 128*128128∗128 pixel và 182*182182∗182 pixel, phần lề xung quanh mặt được lấy thêm 10 pixel nữa cho mỗi ảnh.
Cuối cùng là công đoạn khử nhiễu. Lúc này, sức người đã được đổ ra với nhiệm vụ là xóa đi những bức hình không phải của cùng một người trong từng thư mục. Việc này mất khá nhiều thời gian và nhàm chán.
Tuy nhiên, kết quả thu về thì luôn làm ta trở lên phấn trấn. Sau quá trình khử nhiễu, hơn 23 nghìn ảnh đã được thu thập trên hơn 1000 người. Con số này cũng đáng kể và có giá trị nghiên cứu. Bộ dữ liệu này tương tự như bộ dữ liệu Labeled Faces in the Wild(LFW) với hơn 13 nghìn ảnh của 5749 người, tuy nhiên nó nhiều dữ liệu hơn và nó dành riêng cho người Việt.
Cuối cùng, chúng ta sẽ phần tích một chút về bộ dữ liệu mới này.
Tổng kết
Bộ dữ liệu thu được bao gồm 23105 khuôn mặt của 1020 người có mặt trên Wikipedia Việt Nam. Trong trung bình 1 người là có gần 20 ảnh, có 7 người có số ảnh ít nhất là 2 ảnh, người nhiều nhất có 105 ảnh. Số lượng phân bố như sau:
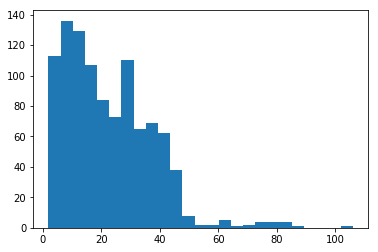
Một đặc điểm nữa của bộ dữ liệu này cần quan tâm tới đó là ảnh thu thập của cùng người có thể ở các thời kỳ rất khác nhau, hoàn cảnh rất khác nhau, có ảnh lúc trẻ có ảnh lúc già, có ảnh đen trắng có ảnh màu. Dưới đây là một số ví dụ(theo thứ tự từ trái qua phải từ trên xuống dưới là Đại tướng Võ Nguyên Giáp- nhà thơ Huy Cận- anh hùng Phạm Tuân- Xuân Bắc- Vân Dung- Xuân Hinh):

Bộ dữ liệu cũng đã được sử dụng thành công trong một cuộc thi về nhận diện người nổi tiếng do AIVIVN tổ chức hồi tháng 3/2019. Dưới đây là kết quả của cuộc thi.
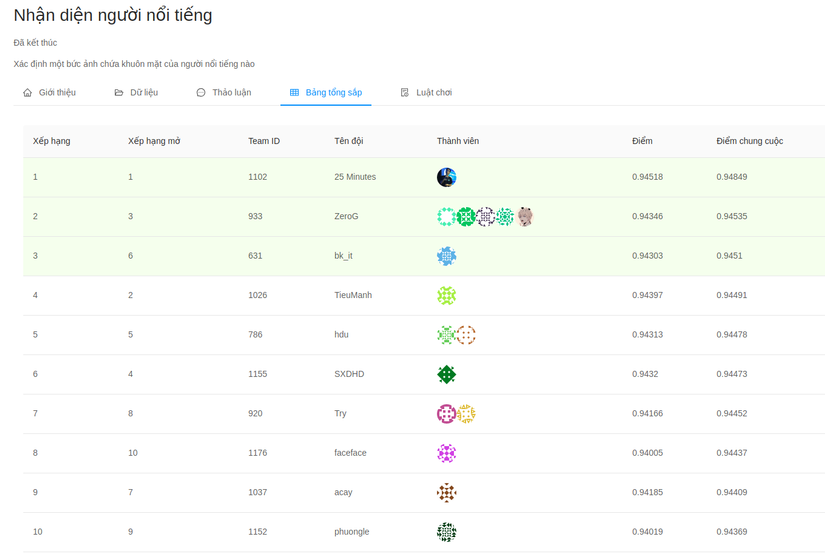
Hiện tại, bộ dữ liệu đã được public hoàn toàn tại đây cho mục đích học tập và nghiên cứu các bài toán liên quan tới nhận diện mặt người cho người Việt.
Mình hy vọng, với bộ dữ liệu này kết hợp với các kĩ thuật như transfer learning, fine-tuning,… sẽ giúp bạn đạt được kết quả tốt hơn cho các bài toán dành riêng cho người Việt.
Bình luận