Source code tham khảo:
Trong bài này chúng ta sẽ cùng nhau tìm hiểu mối quan hệ 1-1 và cách mapping nó trong hibernate như thế nào.
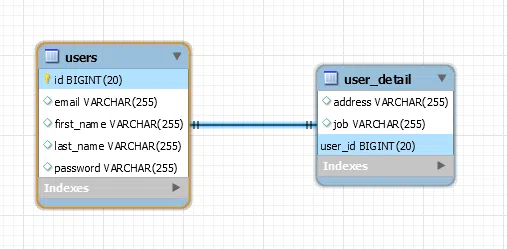
Cùng bắt đầu với một ví dụ về user trong hệ thống. Đầu tiên ta có bảng Users, bảng này lưu các thông tin ít khi bị thay đổi của user, bảng user gồm các thuộc tính như (email, first_name, last_name, password), bảng này có thể dùng để phục phụ chức năng đăng nhập. Ta có bảng thứ hai là user_detail, bảng này chứa các thông tin thường xuyên thay đổi của user như address, job…bảng này sẽ chứa khóa ngoại liên kết với bảng user. Chúng ta có quan hệ giữa 2 bảng này như sau:
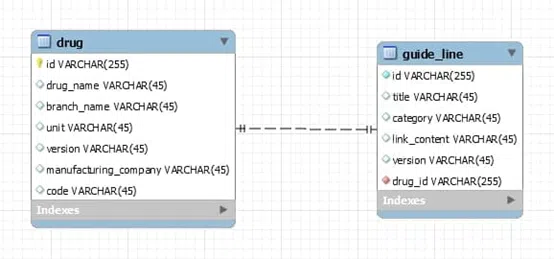
Cùng đến với ví dụ thứ hai về mối quan hệ của bảng drug (thuốc) và bảng guide_line(hướng dẫn sử dụng thuốc). Mỗi một loại thuốc có thể có duy nhất một hướng dẫn sử dụng thuốc đó.
Sau đây là cách Mapping Entity cùng với Hibernate + Spring boot
Ta có 2 entity sau
Users Entity
public class Users {
//...
@NaturalId
private String email;
@OneToOne(mappedBy = "user", cascade = CascadeType.ALL, orphanRemoval = true)
@PrimaryKeyJoinColumn
private UserDetail userDetail;
public void setUserDetail(UserDetail userDetail) {
userDetail.setUser(this);
this.userDetail = userDetail;
}
//...
}
UserDetail Entity
@Table
@Entity
@Data
@NoArgsConstructor
public class UserDetail {
//...
@OneToOne(fetch = FetchType.LAZY)
@MapsId
@JsonIgnore
private Users user;
//...
}
Chú thích
- FetchType.LAZY khi lấy đối tượng UserDetail từ database sẽ không lấy theo đối tượng User, ngược lại FetchType.EAGER sẽ lấy theo đối tượng User khi lấy đối tượng UserDetail từ database.
- @MapsId được sử dụng để chỉ định primary key trong quan hệ 1-1 và 1-N, trong ví dụ trên primary key của Users sẽ là primary key của bảng UserDetail
- MappedBy = “user” - thuộc tính mappedBy trong User entity dùng để cho JPA biết rằng thực thể User không chứa khóa ngoại, hãy tìm kiếm khóa ngoại trong thực thể UserDetail tại trường có tên là user. Khóa ngoại đó được chỉ ra bới giá trị của thuộc tính name trong annotation @JoinColumn.
- Trong mối quan hệ hai chiều (bi-directional), chúng ta dùng chú thích @OneToOne ở cả hai entity nhưng chỉ một entity là chủ sở hữu (owner) của mối quan hệ (relationship). Thông thường, entity con là chủ sở hữu của mối quan hệ và thực thể cha là bên nghịch đảo của mối quan hệ.
- Chủ sở hữu của mối quan hệ (entity UserDetail) chứa chú thích @JoinColumn để chỉ ra cột nào là khóa ngoại và entity nào là nghịch đảo của mối quan hệ (entity User). Entity nghịch đảo này sẽ chứa thuộc tính mappedBy để chỉ ra rằng mối quan hệ được ánh xạ bởi thực thể còn lại.
- @NaturalId chỉ ra cột được dùng như là id, hibernate sẽ cung cấp các api loading entity theo cột này và mang lại các lợi ích giống như loading bằng cột id.
NaturalIdLoadAccess cung cấp 2 cách lấy entity:
- load: lấy reference của entity, entity state đã được khởi tạo trước đó
- getReference: lấy reference của entity, entity state không cần khởi tạo trước đó, nếu entity state đã nằm trong session reference của entity sẽ được trả về, nếu entity chưa nằm trong session và entity hỗ trợ proxy thì uninitialized proxy sẽ được khởi tạo và trả về, trường hợp cuối cùng entity không hỗ trợ proxy thì entity sẽ được load từ database
Natual id cho phép cache entity ở mức session và level 2.
Sau đó ta thực thi ứng dụng như sau:
@Transactional
public void generateUsers() {
User u1 = new User("John", "john@gmail.com");
UserDetail ud1 = new UserDetail("Developer", "1 Ngô Quyền, Hà nội");
u1.setUserDetail(ud1);
em.persist(u1);
}
Ta thu được log query như sau
insert into user (email, fullname, id) values (?, ?, ?)
insert into user_detail (address, job, user_id) values (?, ?, ?)
Sử dụng mối quan hệ 1-1 khi nào
Tối đa hóa caching bằng việc phân hóa dữ liệu theo chiều dọc.
Cơ sở dữ liệu thường lưu bộ nhớ đệm theo trang, thay vì cột. Ví dụ: Trong 1 câu truy vấn nếu số lượng các trường lấy ra tương đối ít so với số trường của bảng thì cơ sở dữ liệu vẫn sẽ lưu vào bộ nhớ đệm toàn bộ hàng đó, hệ quả là những thông tin không thực sự cần thiết vẫn sẽ được lưu trong bộ nhớ đệm. Để giải quyết vấn đề này chúng ta có thể nghĩ tới phương án phân dùng dữ liệu theo chiều dọc. Những trường thường được sử dụng hơn sẽ được tách ra 1 bảng, những trường ít được sử dụng hơn sẽ nằm trong bảng còn lại, hai bảng này có mối quan hệ 1-1 với nhau
Phân tách vùng dữ liệu thường xuyên bị khóa ra khỏi vùng dữ liệu còn lại
Thông thường cơ sở dữ liệu chỉ có thể khóa toàn bộ hàng, không thể khóa một vài trường. Bằng việc phân hóa dữ liệu theo chiều dọc như cách thứ nhất chúng ta có thể đảm bảo khóa được các trường khi cần thiết mà vẫn đảm bảo tính sẵn sàng của các trường còn lại.
Vấn đề bảo mật
Đôi khi có những trường cần được bảo mật, chúng ta có thể tách những trường đó ra một bảng riêng.
Do nghiệp vụ
Do vấn đề ngữ nghĩa của nghiệp vụ chúng ta cần chia tách ra 2 bảng riêng thay vì gộp chúng vào làm một.
Bình luận