Người dịch: Hoàng Văn Cương, lập trình viên Spring Boot, Techmaster Việt nam
Bài viết gốc bằng tiếng Anh ở dataschool.com/sql-optimization/how-indexing-works/
Đánh chỉ mục là gì?
Đánh chỉ mục giúp các cột được truy vấn nhanh hơn bằng cách tạo ra những chỉ dẫn tới nơi mà dữ liệu được lưu trữ trong CSDL.
Hãy tưởng tượng bạn muốn tìm kiến một phần thông tin nhỏ trong CSDL. Để lấy được nó, máy tính sẽ phải đi tìm từng dòng một cho đến khi tìm được. Nếu dữ liệu mà bạn đang tìm kiếm ở tận cuối cùng thì việc truy vấn sẽ tốn rất nhiều thời gian.
Ví dụ như hình dưới:
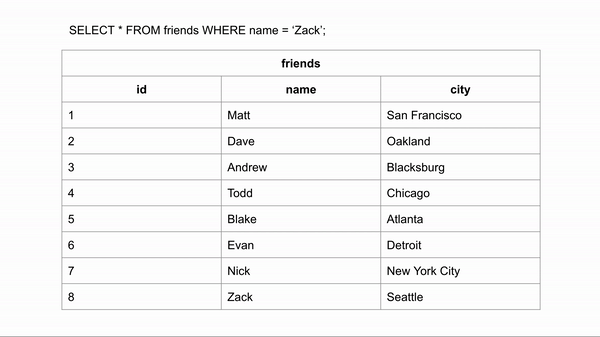
Nếu bảng được sắp xếp tên theo anphabet, chúng ta có thể tìm kiếm nhanh hơn nhiều vì có thể bỏ qua một số dòng nhất định. Để tìm “Zack” với dữ liệu đã sắp xếp theo anphabet chúng ta có thể bắt đầu từ ở giữa và xét xem tên đó ở nửa trên hay nửa dưới. Sau đó lại bắt đầu tìm kiếm từ ở giữa của nửa đó và cứ tiếp tục như vậy cho đến khi tìm thấy.
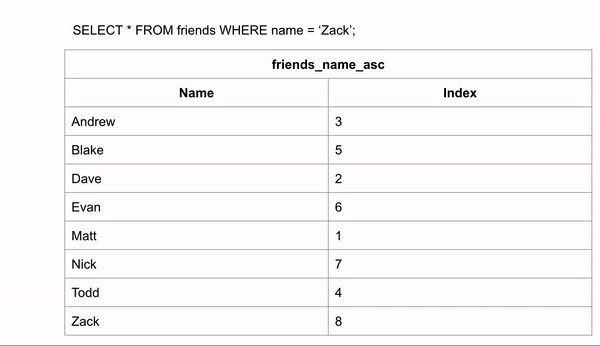
Việc tìm kiếm sẽ chỉ mất 3 lần so sánh để tìm được đáp áp chính xác thay vì 8 ở dữ liệu chưa được đánh chỉ mục.
Các chỉ mục cho phép chúng ta tạo các danh sách được sắp xếp mà không cần phải tạo một bảng với dữ liệu được sắp xếp mới. Điều này giúp ta tiết kiệm rất nhiều bộ nhớ.
Vậy thực sự đánh chỉ mục là gì?
Một chỉ mục là một cấu trúc mà trong đó chứa đựng trường mà chỉ mục đang sắp xắp và liên kết từ nó tới dữ liệu tương ứng ở bảng dữ liệu gốc – nơi mà dữ liệu thực sự được lưu trữ. Có thể hiểu chỉ mục giống như một cuốn sách thần kỳ, nó lưu trữ thông tin theo thứ tự ta ghi vào và có hai chế độ đọc. Chế độ nguyên bản nơi dữ liệu như đúng chú ta ghi (bảng dữ liệu gốc) và chế độ sắp xếp giúp ta tìm kiếm thông tin nhanh hơn (cấu trúc chỉ mục).
Để dễ hình dung, chúng ta dùng ví dụ ở trên và xem cách mà chỉ mục kết nối tới bảng dữ liệu gốc ra sao:
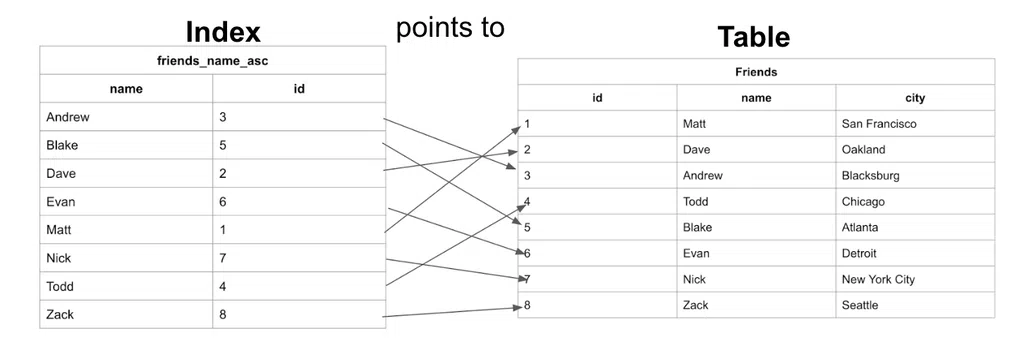
Chúng ta thấy rằng, bảng Friends được sắp xếp theo id tăng dần mỗi khi ta thêm dữ liệu mới. Còn bảng Index được lưu trữ với việc sắp xếp tên theo anphabet.
Các kiểu đánh chỉ mục
Có 2 kiểu đánh chỉ mục cho CSDL:
- Clustered – Đánh theo cụm
- Non-clustered – Đánh không phân cụm
Cả hai kiểu trên đều lưu trữ và tìm kiếm theo kiểu B-trees, một cấu trúc dữ liệu tương tự với cây nhị phân (binary tree). Mỗi B-tree là “ cấu trúc dữ liệu cây tự cân bằng nơi đảm bảo việc dữ trữ dữ liệu đã sắp xếp và cho phép tìm kiếm, truy cập tuần tự, thêm và xóa với với thời gian theo log(n)”. Về cơ bản, nó tạo một cây – giống kiểu cấu trúc mà dữ liệu được sắp xếp để tìm kiếm nhanh.
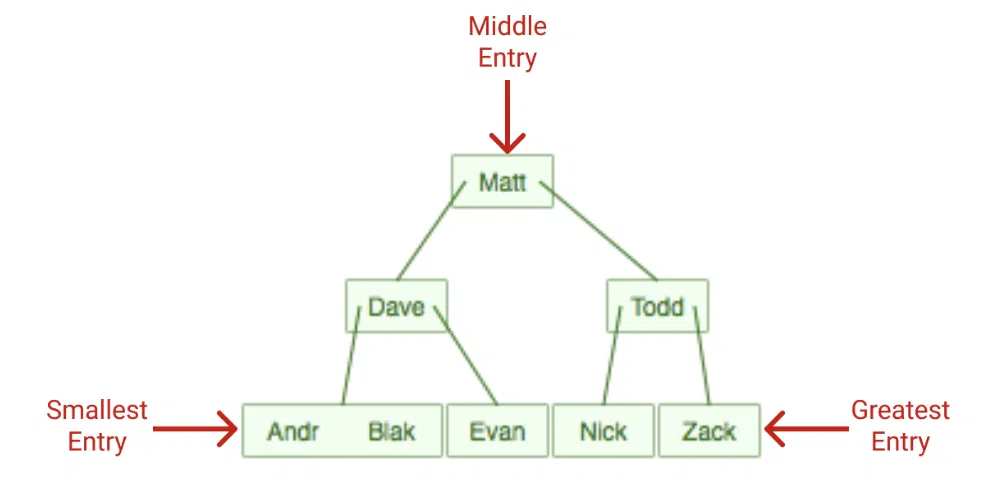
Trên đây là một B-tree của chỉ mục. Đầu vào nhỏ nhất là ở điểm ngoài cùng bên trái, lớn nhất là ngoài cùng bên phải. Tất cả truy vấn có thể bắt đầu ở node trên cùng và đi dần xuống, nếu node mục tiêu nhỏ hơn node hiện tại thì sẽ di chuyển sang bên trái, nếu node mục tiêu lớn hơn thì di chuyển sang bên phải. Ở ví dụ trên nó sẽ di chuyển như sau: Matt => Todd => Zack.
Để tăng tích hiệu quả, rất nhiều B-tree sẽ giới hạn số phần tử bạn nhập vào một mục. B-tree sẽ tự làm việc đó và không yêu cầu giới hạn dữ liệu cột. Ở ví dụ trên, B-tree giới hạn số mục ở 4.
Đánh chỉ mục theo cụm (Clustered Indexes)
Chỉ mục được phân cụm là chỉ mục duy nhất trên mỗi bảng sử dụng khóa chính để tổ chức dữ liệu trong bảng. Nó đảm bảo rằng khóa chính được lưu trữ theo thứ tự tăng dần, đó cũng là thứ tự mà bảng giữ trong bộ nhớ.
- Chỉ mục cụm không nhất thiết phải khai báo rõ ràng.
- Được tạo ngay khi bảng được tạo ra.
- Sử dụng khóa chính theo thứ tự tăng dần.
Tạo Clustered Indexes
Đánh chỉ mục cụm – clustered index sẽ được tạo tự động khi khóa chính được lựa chọn:
CREATE TABLE friends (id INT PRIMARY KEY, name VARCHAR, city VARCHAR);Khi được điền đủ dữ liệu, bảng sẽ như bên dưới:
Bảng Friends được tạo ra sẽ có đánh chỉ mục cụm tự động như đã nêu và được tổ chức xung quanh khóa chính “id” gọi là “friends_pkey”:
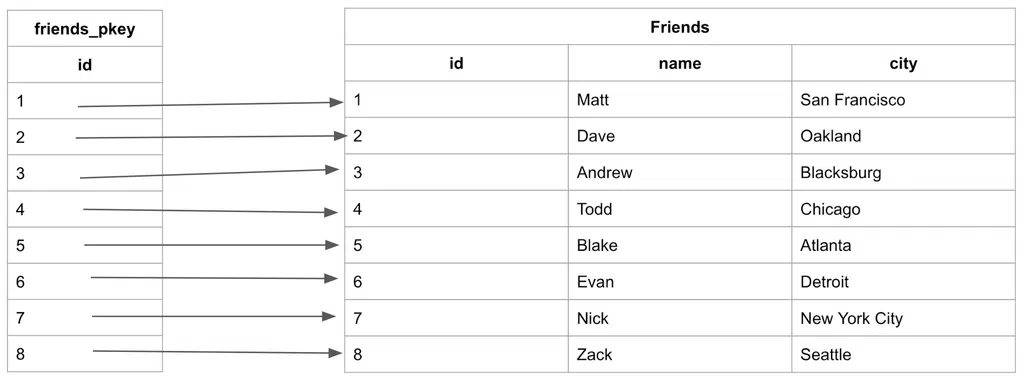
Tuy nhiên, để tìm kiếm cho “name” hay “city” ở trong bảng, ta bắt buộc phải tìm kiếm tuần tự do những cột đó chưa có chỉ mục. Đó là lý mà mà đánh chỉ mục không phân cụm - non-clustered indexes trở nên hữu dụng.
Chỉ mục không phân cụm (Non-Clustered Indexes)
Chỉ mục không phân cụm là các tham chiếu được sắp xếp cho một trường cụ thể từ bảng chính và nó chứa các con trỏ chỉ về mục gốc ở bảng chính. Ví dụ ở đầu bài chính là một chỉ mục không phân cụm:
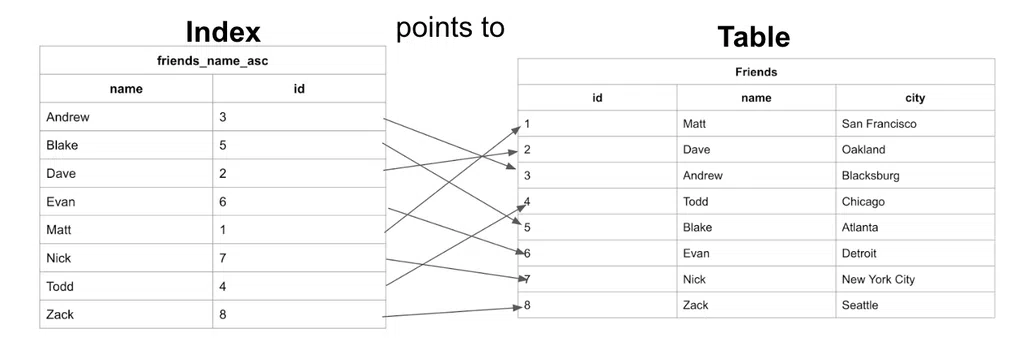
Thông thường nó sẽ tăng tốc việc truy vấn bằng cách tạo ra các cột có thể tìm kiếm dễ dàng. Non-clustered indexes có thể tạo ra bởi data analysts/developers sau khi một bảng được tạo ra và điền thông tin.
Note: Chỉ mục không phân cụm không phải là bảng mới. Nó giữ trường dùng để sắp xếp và một con trỏ, trỏ từ mỗi mục trong đó tới mục chứa đầy đủ các tường ở bảng gốc.
Bạn có thể tưởng tượng nó giống như mục lục của một cuốn sách. Các index sẽ chỉ đến vị trí chứa nội dung mà bạn tìm kiếm trong cuốn sách.

Non-clustered indexes sẽ chỉ đến địa chỉ bộ nhớ của dữ liệu thay vì tự lưu trữ. Việc này làm cho việc truy vấn chậm hơn so với clustered indexes nhưng thông thường sẽ nhanh hơn việc không đánh chỉ mục. Bạn có thể tạo ra nhiều non-clustered indexes. Tại 2008, bạn có thể tạo 999 non-clustered indexes tronng SQL Server và không giới hạn trong PostgresSQL.
Tạo Non-Clustered Databases(PostgreSQL)
Để tạo một chỉ mục cho việc sắp xếp tên theo anphabet:
CREATE INDEX friends_name_asc ON friends(name ASC);Câu lệnh trên sẽ tạo ra một chỉ mục có tên “friends_name_asc” để chỉ ra rằng chỉ mục này lưu tên từ “friends” và lưu trữ theo anphabet tăng dần.
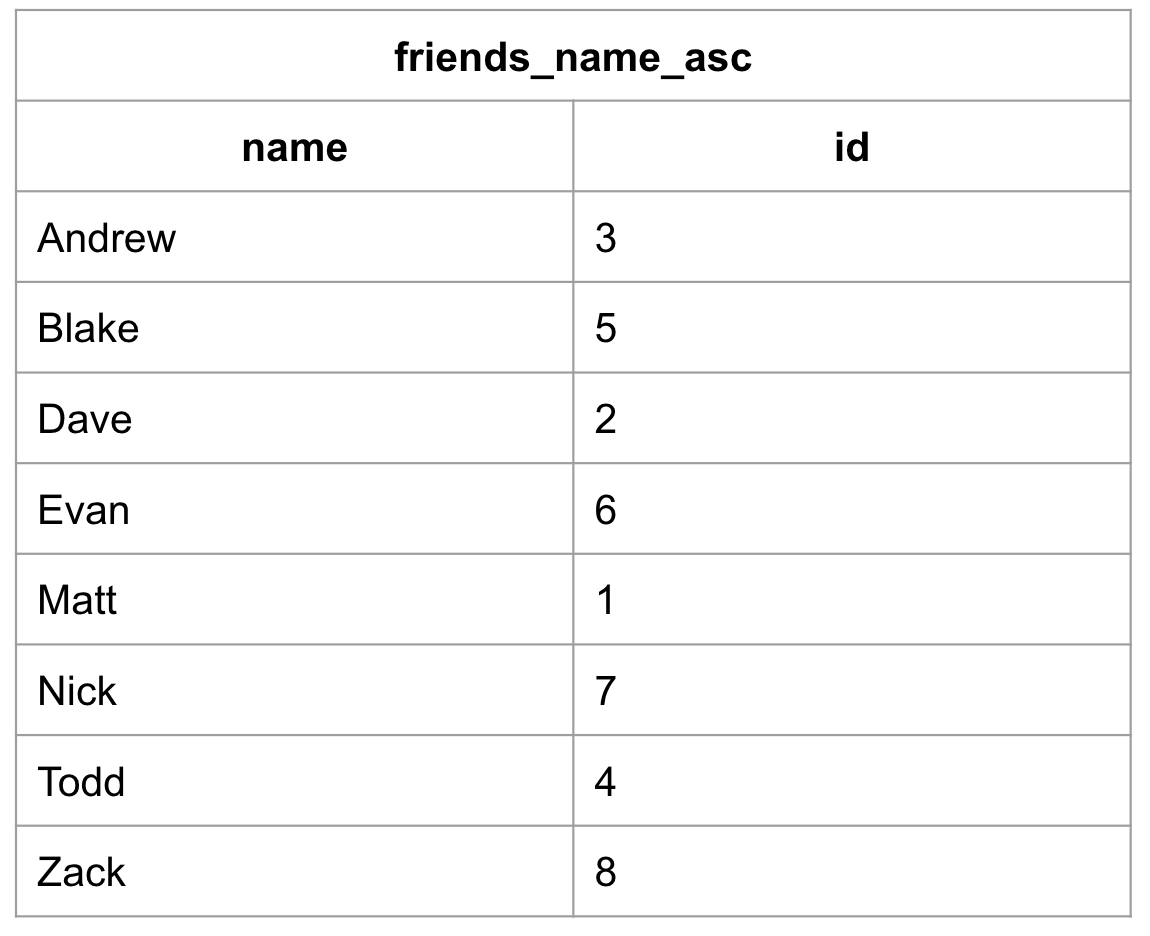
Chú ý cột “city” không xuất hiện trong chỉ mục. Đó là vì các chỉ mục không lưu trữ tất cả các thông tin từ bảng gốc. Cột “id” sẽ là con trỏ để trỏ ngược về bảng dữ liệu gốc. Logic của con trỏ như sau:
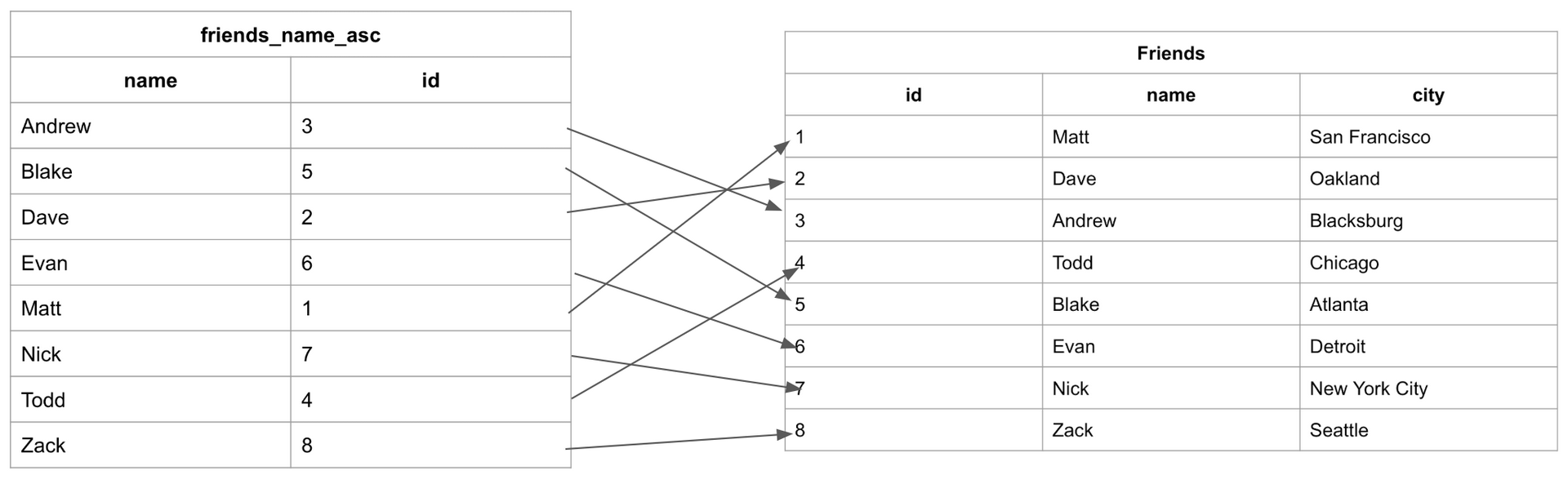
Tạo Indexes
Trong PostgresSQL, lệnh “\d” dùng để liệt kê thông tin bảng gồm: tên bảng, tên cột, kiểu dữ liệu cột, indexes và các ràng buộc.
Thông tin bản Friends như sau:
Query providing details on the friends table: \d friends;

Từ ảnh trên, “friends_name_asc” bây giờ là một chỉ mục liên quan của bảng “friends”. Điều đó có nghĩa là kế hoạch truy vấn - kế hoạch SQL tạo ra khi xác định cách tốt nhất để thực hiện truy vấn, sẽ bắt đầu sử dụng chỉ mục khi các truy vấn đang được thực hiện. Ta có “friends_pkey” cũng là chỉ mục vì nó được tạo ra tự động dựa vào khóa chính.
Ta có “friends_city_desc” index cũng được tạo ra tương tự như names index:
CREATE INDEX friends_city_desc ON friends(city DESC);Tìm kiếm Indexes
Ta có thể dùng non-clustered indexes sau khi chúng được tạo. Các chỉ mục sử dụng cách tìm kiếm tối ưu là tìm kiếm nhị phân - binary search. Cách tìm kiếm này hiệu quả với B-tree vì nó được thiết kế để tìm kiếm bắt đầu từ mục ở giữa. Chúng ta biết rằng các mục bên trái sẽ nhỏ hơn hoặc là ở trước mục hiện tại. Còn bên phải sẽ lớn hơn hoặc ở phía sau.
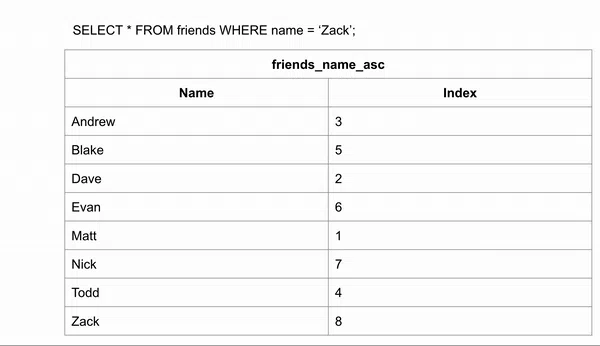
So sánh việc sử dụng phương pháp này để truy vấn ở ví dụ đầu tiên, chúng ta đã giảm số lần tìm kiếm từ 8 xuống 3. Nếu sử dụng phương pháp này cho bảng có 1,000,000 chỉ mục thì nó giảm xuống chỉ còn 20 bước với binary search.
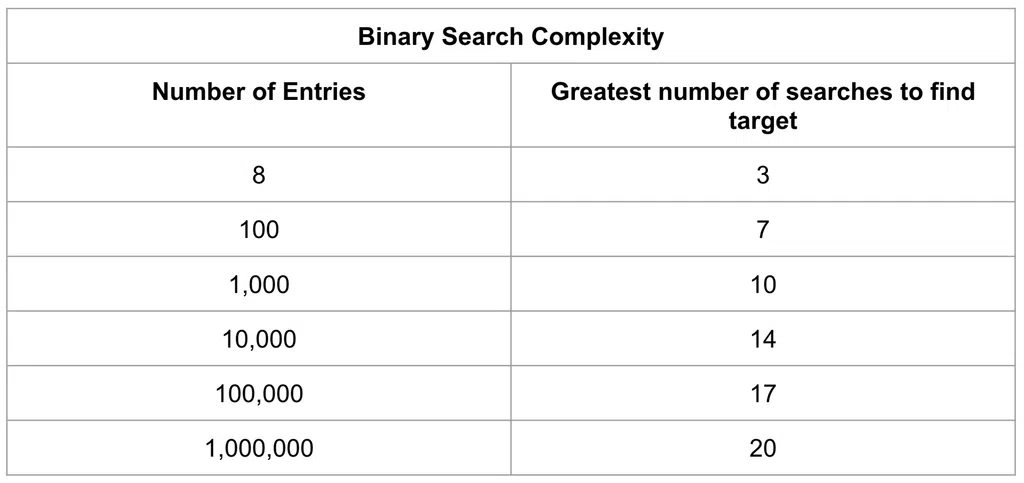
Khi nào nên sử dụng Indexes
Indexes được sinh ra để tăng tốc hiệu năng cho CSDL do đó hãy dùng khi nó có cải thiện đáng kể hiệu năng của CSDL. Vì CSDL luôn trở nên lớn hơn theo thời gian do đó chúng ta càng nhìn thấy rõ hơn lợi ích của đánh chỉ mục.
Khi nào KHÔNG nên sử dụng Indexes
Khi dữ liệu được ghi vào CSDL, bảng gốc được update trước tiên rồi sau đó đến các chỉ mục. Mỗi khi việc ghi dữ liệu diễn ra thì không thể sử dụng chỉ mục cho đến khi nó được update. Nếu dữ CSDL luôn luôn nhận và ghi dữ liệu thì chỉ mục sẽ không bao giờ được dùng đến. Đó là lý do vì sao chỉ mục chỉ được dùng cho CSDL của các nhà kho (nơi có dữ liệu update định kỳ) chứ không phải CSDL của sản phẩm (nơi có thể luôn tiếp nhận dữ liệu).
NOTE: bản mới nhất của Postgres (đang ở bản beta) sẽ cho phép bạn truy vấn ngay cả khi chỉ mục đang được update.
Kiểm tra hiệu suất
Để kiểm tra xem đánh chỉ mục có giúp giảm thời gian hay không, bạn có thể chạy tệp lệnh truy vấn, ghi thời gian nó cần để hoàn thành và sau đó tạo chỉ mục và chạy lại bài test.
Dùng EXPLAIN ANALYZE nếu bạn dùng PostgreSQL:
EXPLAIN ANALYZE SELECT * FROM friends WHERE name = 'Blake';Với một CSDL nhỏ ta có kết quả sau:

Kết quả cho bạn biết phương pháp tìm kiếm nào từ kế hoạch truy vấn đã được chọn và việc lập kế hoạch và thực hiện truy vấn mất bao lâu.
Chỉ tạo duy nhất một chỉ mục tại một thời điểm vì không phải tất cả các chỉ mục sẽ giảm bới thời gian truy vấn
- Kế hoạch truy vấn của PostgreSQL khá hiệu quả do đó tạo chỉ mục mới có thể không ảnh hưởng hiệu suất tốc độ truy vấn.
- Thêm chỉ mục sẽ đồng nghĩa với việc lưu trữ thêm dữ liệu
- Thêm chỉ mục làm tăng thời gian update CSDL sau khi thêm dữ liệu.
Nếu thêm chỉ mục không làm giảm thời gian truy vấn thì hãy loại bỏ nó. Để loại bỏ một chỉ mục ta dùng lệnh DROP INDEX:
DROP INDEX friends_name_asc;Tổng quan của CSDL bây giờ sẽ như sau:

Nó cho ta thấy câu lệnh loại bỏ index đã thành công.
Tổng kết
- Lập chỉ mục có thể làm giảm đáng kể thời gian của các truy vấn
- Mỗi bảng có khóa chính đều có một chỉ mục nhóm
- Mỗi bảng có thể có nhiều chỉ mục không phân cụm để hỗ trợ việc truy vấn
- Các chỉ mục không phân cụm giữ các con trỏ quay lại bảng chính
- Không phải mọi cơ sở dữ liệu sẽ được hưởng lợi từ việc lập chỉ mục
- Không phải mọi chỉ mục sẽ tăng tốc độ truy vấn cho cơ sở dữ liệu
Bình luận